Key Takeaways
- How Medical Imaging Training Data supports diagnostic AI reliability across modalities, populations, and clinical environments
- Why medical image annotation quality directly affects model performance, validation strength, and downstream clinical trust
- How radiology training data must be structured, versioned, and governed for reproducible AI development
- Why healthcare AI datasets require traceability, de-identification, access controls, and cross-border governance
- How diagnostic AI teams can reduce dataset rework, improve validation cycles, and lower model risk through stronger data infrastructure
Diagnostic AI systems are only as reliable as the imaging datasets used to train, validate, and monitor them. Model architecture, compute capacity, and deployment workflows matter, but the commercial and clinical value of diagnostic AI depends heavily on whether the underlying medical imaging training data reflects real clinical variation. That includes modality diversity, scanner differences, patient demographics, disease prevalence, annotation quality, and longitudinal data governance. Without these foundations, AI tools may perform well in development but fail to generalize across hospitals, radiology workflows, or patient populations.
The Training Data Gap in Diagnostic AI Systems
Diagnostic AI development often begins with a model performance objective, but the real constraint is usually the dataset. A system trained on narrow, inconsistent, or poorly annotated imaging data may produce strong internal metrics while failing under real-world clinical variation. FDA’s public list of AI and machine learning-enabled medical devices shows how radiology has become one of the most active areas for AI-enabled medical device development, which increases the importance of disciplined training data infrastructure.
Why Model Performance Depends on Medical Imaging Training Data
Medical Imaging Training Data determines what a diagnostic AI system learns to recognize, ignore, prioritize, or misclassify. In radiology, clinically meaningful variation appears across modalities such as CT, MRI, X-ray, ultrasound, mammography, and pathology imaging. It also appears across scanner vendors, acquisition protocols, reconstruction methods, contrast usage, patient age, disease stage, and clinical setting. Therefore, model performance is not only a function of algorithm design. It is a function of how completely the dataset represents the diagnostic reality the model will encounter.
Where Internal Imaging Archives Fall Short for AI Development
Internal imaging archives can provide valuable source material, but they are rarely AI-ready without significant preparation. PACS systems and radiology information systems were designed for clinical operations, not for machine learning dataset construction. Imaging studies may contain inconsistent metadata, incomplete labels, duplicate examinations, protocol variation, and unstructured report text. As a result, internal archives often require extraction, de-identification, normalization, annotation, and quality review before they become usable radiology training data for diagnostic AI development.
Medical Imaging Training Data as a Diagnostic AI Foundation
Medical Imaging Training Data becomes commercially valuable when it is treated as a governed AI asset, not as a static collection of image files. Diagnostic AI teams need datasets that support training, validation, benchmarking, regulatory review, and post-deployment monitoring. RSNA’s LumbarDISC dataset paper illustrates the importance of multi-institutional imaging datasets, expert annotation, and structured classification for medical imaging AI research. These principles apply directly to enterprise diagnostic AI pipelines.
Building Representative Datasets Across Modalities and Patient Populations
Representative healthcare AI datasets must capture the diversity of real clinical practice. A model trained primarily on one hospital, one scanner vendor, one geography, or one demographic group may underperform when deployed elsewhere. Dataset design should account for modality mix, disease prevalence, rare findings, comorbidities, image quality variation, and patient population differences. In practice, this means dataset teams must evaluate not only how much data they have, but whether the data reflects the clinical environments where the AI system will be used.
Structuring Radiology Training Data for Model Reliability
Radiology training data requires structured organization across studies, series, images, clinical labels, reports, metadata, and annotation outputs. A chest CT dataset for pulmonary embolism detection, for example, may require series-level classification, slice-level localization, report-derived labels, contrast protocol metadata, and exclusion criteria. Without structured relationships between images and labels, model development becomes difficult to reproduce. Reliable diagnostic AI depends on dataset schemas that preserve clinical context while allowing scalable training and validation workflows.
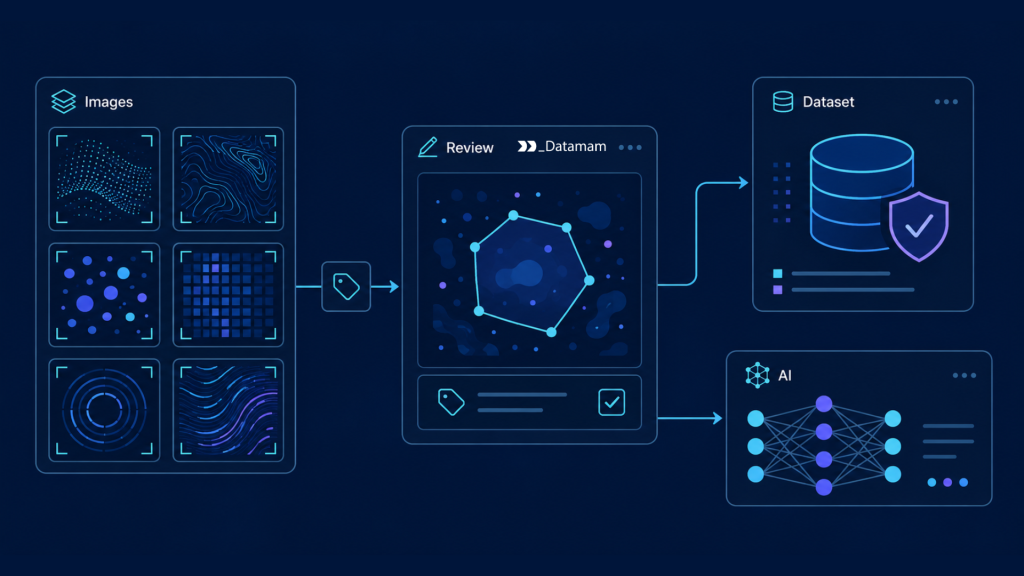
Using Medical Image Annotation to Improve Diagnostic Signal Quality
Medical image annotation transforms raw images into diagnostic training signals. Depending on the use case, annotation may involve classification labels, segmentation masks, bounding boxes, key points, anatomical landmarks, measurement extraction, or report-grounded labels. Annotation quality directly affects model behavior because inconsistent labels teach inconsistent patterns. Therefore, annotation workflows should include expert review, inter-reader agreement checks, adjudication rules, quality sampling, and version control. Medical image annotation is not a clerical task. It is a clinical signal engineering process.
External Data Requirements for Healthcare AI Datasets
Healthcare AI datasets often need to extend beyond one organization’s internal imaging archive to improve generalization and reduce bias. External data may come from research repositories, hospital collaborations, imaging networks, public datasets, or curated commercial partnerships. External datasets can expand coverage, but they require disciplined governance and validation.
Sourcing Imaging Data Across Hospitals, Research Repositories, and Public Datasets
External imaging data can improve dataset diversity, but sourcing must be controlled. Each source may differ in consent basis, data access terms, de-identification standard, modality coverage, metadata quality, and permitted use. A diagnostic AI team sourcing healthcare AI datasets across hospitals or repositories must document provenance, clinical context, acquisition method, and usage constraints. Without this source-level discipline, organizations may build training datasets that are difficult to audit, reproduce, or defend during regulatory and clinical review.
Normalizing Imaging Metadata, Study Types, and Clinical Labels
Medical imaging metadata is often inconsistent across institutions. DICOM fields may vary, study descriptions may use local naming conventions, and labels may be derived from reports, billing codes, annotations, or structured clinical systems. Normalization aligns modality, body region, study type, acquisition protocol, scanner information, contrast status, timestamps, and clinical labels into a consistent schema. This allows radiology training data to be compared and analyzed across sites. Without normalization, model performance differences may reflect metadata inconsistency rather than true diagnostic capability.
Managing Data Diversity Across Geography, Equipment, and Care Settings
Dataset diversity must be measured, not assumed. A large dataset may still be narrow if most images come from similar scanners, academic hospitals, urban populations, or high-resource settings. Diagnostic AI systems may later be deployed in community hospitals, outpatient imaging centers, international environments, or low-resource settings with different acquisition patterns. Accordingly, healthcare AI datasets should be profiled across geography, equipment, institution type, patient groups, disease categories, and image quality. Diversity analysis helps identify where additional data is needed before model validation.
Infrastructure Requirements for Medical Imaging Training Data Pipelines
Medical imaging dataset development requires infrastructure that can handle large files, sensitive patient data, complex metadata, expert annotation, and reproducible model training. The pipeline must support both clinical safeguards and engineering scalability. A 2025 review on generative AI in medical imaging emphasizes challenges, including data scarcity, standardization, generalization under domain shift, privacy concerns, and regulatory hurdles. These issues make dataset infrastructure central to diagnostic AI reliability.
Continuous Data Intake for Imaging, Reports, and Metadata
Training data pipelines must ingest imaging studies, radiology reports, structured metadata, and annotation outputs in a controlled workflow. Intake may involve secure transfer from PACS exports, DICOM routers, research repositories, cloud storage, or hospital data environments. Orchestration tools such as Airflow can manage intake jobs, retries, dependencies, and processing stages. At scale, controlled intake ensures that Medical Imaging Training Data is not assembled through ad hoc file movement, but through documented, repeatable processes that preserve provenance and access controls.
Validation Controls for Image Quality, Label Consistency, and Dataset Completeness
Validation controls prevent unusable or misleading data from entering training workflows. Image-level validation may check modality, resolution, corrupted files, missing series, slice count, acquisition protocol, and image quality. Label-level validation may check annotation completeness, label conflicts, class imbalance, and agreement between report-derived labels and expert annotations. Dataset-level validation may evaluate demographic coverage, site distribution, and missing metadata. These controls reduce the risk that model performance reflects data artifacts rather than clinically meaningful patterns.
Versioning, Lineage, and Reproducibility for Model Training Workflows
Diagnostic AI teams need to reproduce which dataset version trained a specific model. This requires lineage across source files, de-identification steps, annotation versions, transformation logic, exclusion criteria, and train-validation-test splits. Data versioning tools, metadata systems, model registries, and audit logs allow teams to reconstruct how a model was built. Without versioning and lineage, performance claims become difficult to verify, regulatory evidence becomes weaker, and dataset changes may silently alter model behavior across development cycles.
Technology Stack Behind Diagnostic AI Training Data Systems
A mature diagnostic AI data system operates across secure intake, transformation, annotation, storage, governance, and model integration. It must support large imaging objects, clinical metadata, radiologist workflows, and downstream machine learning pipelines. A 2025 framework for responsible, secure, and sustainable healthcare AI emphasizes MLOps, technical infrastructure, governance, education, and change management as pillars for clinical impact. Medical imaging data systems need the same operational discipline.
Collection and Orchestration Using Airflow, Secure Transfer, and Controlled Intake Pipelines
Collection workflows may rely on secure file transfer, DICOM export processes, cloud intake zones, API-based metadata retrieval, and controlled ingestion from hospital systems. Apache Airflow can orchestrate these workflows by managing dependencies, quality checks, de-identification tasks, and routing to annotation or storage environments. Unlike open web data pipelines, medical imaging collection must prioritize permissioning, privacy, and chain-of-custody. Every dataset movement should be logged so teams can verify where data came from and how it entered the pipeline.
Processing and Transformation Through Spark, dbt, and Healthcare ETL Workflows
Processing layers transform raw imaging and metadata into structured datasets. Spark can process large metadata tables, derived imaging features, report text, and annotation outputs at scale. dbt can manage analytical transformations, documentation, and standardized dataset tables. Healthcare ETL workflows may de-identify DICOM headers, normalize study descriptions, parse reports, align labels, and generate dataset manifests. These processes turn fragmented imaging archives into radiology training data that can support model development, validation, and monitoring.
Storage, Governance, and Analytics in Databricks, Snowflake, BigQuery, or Lakehouse Environments
Medical imaging datasets often require a combination of object storage for DICOM or image files and analytical warehouses for metadata, labels, annotations, and audit records. Databricks, Snowflake, BigQuery, or lakehouse environments can support dataset analysis, cohort selection, and model feature workflows. Governance controls should include role-based access, encryption, audit logs, data lineage, retention policies, and metadata catalogs. These controls are essential because healthcare AI datasets involve sensitive clinical information and high-stakes diagnostic use cases.
Commercial Impact of High-Quality Medical Imaging Training Data
The commercial value of Medical Imaging Training Data appears when dataset quality improves model reliability, validation speed, regulatory readiness, and clinical adoption potential. Better data does not guarantee diagnostic AI success, but weak data almost always increases rework, risk, and deployment friction. High-quality datasets help teams reduce false starts, identify model weaknesses earlier, and make performance claims with greater confidence. For diagnostic AI vendors, providers, and research groups, dataset infrastructure becomes a product development accelerator.
Improving Model Generalization Across Clinical Environments
Generalization is one of the most important commercial outcomes for diagnostic AI. A model that performs well at one site but poorly elsewhere creates adoption risk, validation burden, and clinical trust concerns. Representative medical imaging training data helps models learn patterns that remain stable across scanners, protocols, populations, and care settings. Conservative impact often appears as fewer site-specific retraining cycles, stronger external validation readiness, and lower risk of performance degradation during pilot deployments.
Reducing Annotation Rework and Dataset Preparation Time
Medical image annotation is expensive because it requires specialist expertise and structured review. Poor annotation instructions, inconsistent label definitions, and weak quality control create rework that slows development. Clear annotation schemas, adjudication workflows, and validation checks reduce repeated review cycles. At scale, this can shorten dataset preparation timelines and free radiologists, clinicians, and data scientists to focus on clinically meaningful edge cases rather than correcting preventable data inconsistencies.
Supporting Faster Validation Cycles for Diagnostic AI Products
Validation cycles depend on clean dataset splits, consistent labels, representative cohorts, and reproducible preprocessing. When healthcare AI datasets are governed and versioned, teams can run performance testing more efficiently across patient subgroups, sites, scanners, and disease categories. This supports faster identification of performance gaps and clearer evidence generation for clinical stakeholders. In practice, strong dataset infrastructure reduces ambiguity because teams can understand whether performance changes come from model updates, dataset shifts, or annotation revisions.
Risk Exposure When Medical Imaging Training Data Is Incomplete
Incomplete or poorly governed medical imaging data creates clinical, commercial, regulatory, and reputational risk. A diagnostic AI system may appear promising in development, but underperform in real clinical settings if the dataset fails to reflect meaningful variation. A 2025 study on dataset bias in medical AI describes how dataset attributes and acquisition characteristics can enable shortcut learning or hide spurious associations. This is directly relevant to diagnostic AI systems trained on imaging data.
Bias and Performance Drift Across Patient Groups and Imaging Devices
Bias can enter medical imaging datasets through patient selection, site concentration, scanner distribution, disease prevalence, or annotation patterns. A model may perform differently across age groups, sex, race, geographic region, scanner vendor, or imaging protocol. Performance drift can also occur when new devices, protocols, or patient populations differ from the original training set. Teams must monitor dataset composition and subgroup performance because diagnostic AI failure is often uneven rather than uniformly visible across the full population.
Diagnostic Reliability Gaps From Poor Labeling and Weak Annotation Standards
Weak annotation standards create diagnostic reliability gaps. If one radiologist labels findings at the study level while another labels at the lesion level, model targets become inconsistent. If report-derived labels are not reviewed, negation, uncertainty, and historical findings may produce incorrect labels. Also, if segmentation masks vary by reviewer, model boundaries become unstable. Therefore, medical image annotation requires clear protocols, expert calibration, quality sampling, and adjudication to prevent label noise from becoming model risk.
Compliance, Auditability, and Consent Risks in Healthcare AI Datasets
Healthcare AI datasets involve sensitive clinical information and may be subject to privacy, consent, institutional review, data use agreement, and cross-border restrictions. If data provenance is unclear, organizations may struggle to demonstrate that imaging data was sourced, de-identified, transferred, and used appropriately. Auditability is especially important when datasets inform regulated medical devices or clinical decision support systems. Without documentation, even technically strong datasets may become difficult to commercialize or deploy in institutional healthcare settings.
Governance Requirements for Healthcare AI Dataset Development
Governance is not an administrative layer added after dataset creation. It must be built into the data lifecycle from sourcing through annotation, training, validation, and monitoring. WHO’s guidance on ethics and governance of artificial intelligence for health remains a foundational reference for responsible health AI, emphasizing transparency, inclusiveness, accountability, and protection of autonomy. For diagnostic AI, these principles translate into concrete controls around data access, traceability, privacy, and human oversight.
De-Identification, Access Controls, and Audit Logs
Medical imaging datasets must be de-identified carefully because DICOM metadata may contain protected health information, and images may sometimes contain burned-in identifiers or rare clinical features. Access controls should limit who can view images, metadata, labels, and derived datasets. Audit logs should record data access, export, transformation, annotation, and deletion events. These controls reduce privacy risk and help organizations demonstrate that healthcare AI datasets are handled with appropriate institutional discipline.
Data Lineage and Traceability Across Training, Validation, and Testing Sets
Data lineage allows teams to understand how each image moved from the source system to the training set. Traceability should cover source institution, study identifiers, de-identification steps, annotation version, preprocessing logic, inclusion criteria, and dataset split assignment. This is critical because validation results depend on a clean separation between training, validation, and testing data. If leakage occurs, performance estimates may be inflated. Traceability helps diagnostic AI teams maintain confidence in both model metrics and supporting evidence.
Cross-Border Data Considerations in Medical AI Development
Cross-border healthcare AI dataset development introduces additional complexity because privacy rules, consent expectations, data transfer mechanisms, and localization requirements vary by jurisdiction. A dataset collected under one governance framework may not be usable in another market without review. Cross-border controls should document source permissions, transfer basis, storage location, access rights, and permitted model development activities. For global diagnostic AI products, these considerations affect dataset scalability, regulatory strategy, and commercial deployment planning.
Evaluating Medical Imaging Training Data Readiness
Medical Imaging Training Data becomes valuable when it is ready for repeatable model development, not merely when it exists in storage. Readiness depends on coverage, annotation quality, metadata consistency, governance, and integration with AI workflows. Diagnostic AI teams should evaluate whether datasets represent target clinical environments, whether labels match the intended diagnostic task, and whether data lineage supports reproducibility. A readiness review helps identify dataset gaps before they become model failures or validation delays.
How Healthcare AI Teams Assess Dataset Coverage, Quality, and Governance
A structured assessment should evaluate modality coverage, site diversity, patient population representation, scanner distribution, disease prevalence, label quality, annotation agreement, metadata completeness, and missing data patterns. It should also review de-identification methods, access controls, audit logs, retention policies, and data use restrictions. For healthcare AI datasets, technical quality and governance quality are inseparable. A dataset may be large, but if its provenance, labels, or permissions are weak, its operational value is limited.
When Organizations Need a Medical Imaging Dataset Architecture Review
A dataset architecture review becomes useful when teams rely on fragmented imaging exports, inconsistent annotation spreadsheets, unclear dataset versions, or manual cohort selection. The review should assess intake workflows, annotation process design, validation controls, storage architecture, lineage tracking, and model integration readiness. The output should clarify where dataset risk accumulates, where annotation quality may limit performance, and which infrastructure improvements would make radiology training data more reliable for diagnostic AI development.
Conclusion: Medical Imaging Training Data as Diagnostic AI Infrastructure
Diagnostic AI systems depend on data infrastructure as much as algorithmic sophistication. Medical Imaging Training Data must be representative, annotated, normalized, validated, versioned, and governed before it can reliably support clinical AI development. Medical image annotation provides the diagnostic signal. Radiology training data provides the clinical context. Healthcare AI datasets provide the scale and diversity needed for generalization. Ultimately, organizations that treat imaging datasets as governed infrastructure will be better positioned to build diagnostic AI systems that are reproducible, clinically credible, and commercially viable.


