Automated Solution for Contact Information Crawling
Background
A high-profile player in the web analytics field seeking to aggregate contact information from a large number of domain homepages approached us.
Their aim was to offer businesses and individuals access to regularly updated contact information sourced from an extensive array of websites. However, they confronted a host of challenges:
Faced with these obstacles, our task was to design and execute a meticulously structured data extraction, cleaning, parsing, and transformation pipeline that guaranteed high-precision output.
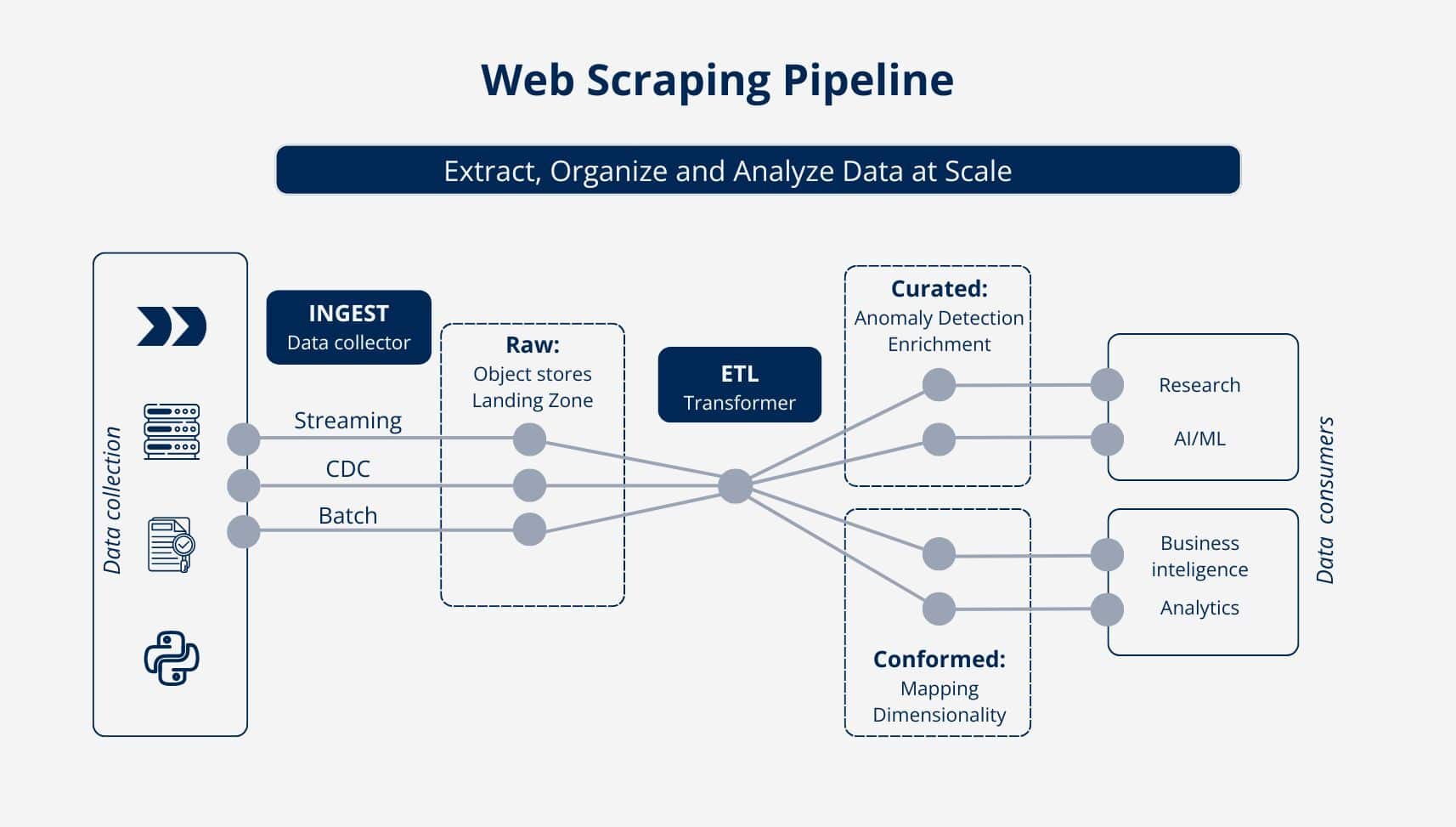

Impact
Our solution had a profound impact on our client’s operation. By providing a consistent, automated, and structured data stream, we allowed the client to significantly streamline their data handling process.
This improved their operational efficiency by 60% (evaluated by internal audit) due to the fact that their data collection and update process improved several times. Our solution allowed the client to cut costs by up to 30% by excluding all manual jobs needed for data collection and converting human resources to different directions.
Automation and significantly reduced errors in data extraction made it possible to automate data quality assessment as well. Our client was able to offer a more comprehensive and accurate service, contributing significantly to their business intelligence solution.
Challenges & Solutions
Challenge
Website Accessibility
Among the vast number of 50,000 domains the client sought to harvest data from, many posed accessibility issues due to diverse technological implementations and strict security protocols.
Solution
Building a Crawling Pipeline
To address the problem with website accessibility we have built a crawling pipeline with the logical tree. If the website was not accessed by common technology of country proxy, the pipeline would try various other options to achieve full data extraction.
Challenge
Data Inconsistency
Websites, with their varying structures and designs, complicated the task of uniformly extracting and structuring contact data. Each website contained 20-40 contact data points, and with no two sites being identical, this task was increasingly complex.
Solution
Dynamic Cleaning Mechanism
Acknowledging the diversity in website structures, we crafted a dynamic parsing algorithm that could adjust to a multitude of designs. Data processing involved parsing collected HTML and JavaScript of superfluous data.
Challenge
Data Accessibility
Often, vital contact information was hidden behind poorly structured HTML elements or dynamic JavaScript elements. This reality complicated the use of standard data extraction methods on a large-scale extraction.
Solution
Data Structuring
We unified the diverse contact data into the client’s preferred JSON format. Additionally, an automated data delivery system was implemented for weekly transfers to the client’s AWS S3 bucket.
Challenge
Datapoint Recognition
Recognizing and categorizing data points posed a significant challenge, given that most of them were not universally structured. For instance, the format and structure of phone numbers varied greatly by country and region.
Solution
Parsing and Data Points Identification
We incorporated over a hundred parsing methodologies to discover and extract all possible data on each website. Each website’s data was scrutinized by quality assurance algorithms to minimize the incidence of false positives and negatives.
Challenge
Historical Data Management
The client required an understanding of when target websites updated their contact information. This need introduced an additional recurring data collection goal, with the task of comparing new data with historical.
Solution
Historical Data Handling
We incorporated a module to extract, clean, and structure contact data from previously crawled domains, providing comprehensive, uniform historical data including all contact information updates as well.
Key Takeaways
Conclusion
The success of this project was significant, leading to a 30% reduction in costs and increasing data acquisition speed several times. This also underlines the fact that data collection at scale with various data sources is already achievable with high accuracy and just requires using modern approaches of data recognition algorithms.
These achievements underline the importance of proficiently handling complex data extraction, structuring, and delivery tasks, especially when dealing with fluctuating and continuously evolving data structures.
Our robust solution not only addressed the client’s immediate requirements but also adapted to potential changes in the web data landscape. We delivered approximately 1,500,000 data points weekly, significantly reducing manual processes and error rates.
Take Action Now
We unlock data’s ability to transform.
Unlock the power of data to drive innovation, optimize operations, and make smarter decisions with Datamam’s comprehensive, integrated solutions.