Key Takeaways
- How Geospatial Training Data supports mapping AI, spatial reasoning, and location intelligence systems
- Why geospatial data labeling is critical for roads, buildings, POIs, land use, imagery, and movement patterns
- How mapping training data must be normalized across regions, coordinate systems, imagery sources, and spatial resolutions
- Why location intelligence data requires governance, lineage, auditability, licensing controls, and cross-border review
- How structured geospatial data pipelines improve model generalization, reduce manual review, and support scalable mapping workflows
Mapping and location AI systems depend on more than satellite imagery, GPS traces, street-level photos, or points-of-interest databases. They require structured, validated, and accurately labeled Geospatial Training Data that teaches models how physical space, infrastructure, land use, movement, and environmental context relate to one another. Whether the use case is navigation, logistics, urban planning, autonomous mobility, insurance risk, climate monitoring, or retail site selection, model performance depends on the quality of the spatial data foundation behind it.
The Training Data Gap in Mapping and Location AI
Mapping AI systems are expected to interpret the physical world with increasing precision. They must classify roads, detect buildings, identify land cover, understand traffic patterns, infer accessibility, and support spatial queries across highly variable environments. NASA Earthdata provides access to large-scale Earth science datasets, showing how geospatial systems depend on structured discovery, metadata, and data access rather than isolated image files.
However, AI systems cannot reason reliably about geography without training data that captures spatial complexity. Roads differ by country. Building footprints vary by density and construction style. Rural, suburban, and dense urban areas produce different spatial patterns. Accordingly, Geospatial Training Data becomes the foundation for mapping AI reliability.
Why Mapping AI Depends on Geospatial Training Data
Mapping AI systems learn from examples of the physical world. If the training data contains incomplete roads, poorly labeled buildings, outdated POIs, inconsistent land-use classes, or narrow geographic coverage, the resulting model may perform well in one region and poorly in another. Geospatial Training Data must therefore reflect differences in terrain, urban form, infrastructure, climate, image quality, and human activity.
In practice, geospatial data labeling teaches models to distinguish what matters spatially. A road is not just a line. It may represent access, directionality, lane structure, surface type, usage pattern, and connectivity. A building footprint may represent residential density, commercial activity, risk exposure, delivery access, or energy demand. The value of mapping AI depends on how accurately these spatial features are represented.
Where Raw Location Data Falls Short for AI Development
Raw location data is often noisy, incomplete, or inconsistent. Satellite images may be affected by cloud cover, resolution limits, seasonal variation, or sensor differences. GPS traces may contain drift, gaps, or biased coverage from uneven user activity. POI databases may be outdated, duplicated, or classified inconsistently. Street-level imagery may contain occlusion, changing signage, or privacy-sensitive content.
As a result, raw location intelligence data must be cleaned, aligned, labeled, and validated before it becomes useful for model training. Without this preparation layer, mapping AI systems may learn artifacts instead of stable spatial patterns. The operational issue is not the absence of geospatial data. It is the shortage of high-quality, AI-ready mapping training data.
Geospatial Training Data as a Foundation for Spatial Intelligence
Geospatial Training Data becomes commercially valuable when it is treated as a structured AI asset rather than a collection of disconnected map files. Mapping and location AI systems require training datasets that connect imagery, vector data, labels, metadata, time, and geography. OGC standards are relevant because geospatial systems depend on interoperability across data formats, services, platforms, and analytical environments.
For enterprise mapping systems, interoperability is not only a technical preference. It determines whether spatial data can move reliably across annotation tools, model training workflows, data warehouses, GIS systems, and downstream analytics products. Without common data structures and documented standards, location intelligence data becomes difficult to integrate, audit, and reuse.
Building Representative Datasets Across Regions and Environments
Representative geospatial datasets must include the environments where the AI system will operate. A routing model trained primarily on dense urban roads may not generalize well to rural areas, informal road networks, construction zones, or regions with different signage conventions. A land-use model trained on one climate zone may underperform in another because vegetation, roof materials, and settlement patterns differ.
Therefore, dataset design should evaluate geographic diversity, imagery conditions, spatial resolution, infrastructure type, and urban-rural balance. For mapping AI, size alone is insufficient. The data must represent the operational geography of the product. A dataset with millions of labels can still be weak if it excludes the regions or spatial conditions where the model will be deployed.
Structuring Mapping Training Data for Model Reliability
Mapping training data should preserve relationships between spatial objects. Roads connect to intersections. Buildings relate to parcels. POIs relate to entrances, neighborhoods, mobility patterns, and commercial activity. Land-use classes relate to zoning, imagery texture, environmental conditions, and economic behavior. If these relationships are not structured, models may classify features but fail to understand spatial context.
Reliable mapping datasets often include imagery tiles, vector geometries, labels, confidence scores, coordinate reference systems, timestamps, source metadata, and reviewer status. This structure allows data scientists to train, test, and validate models while preserving the geographic relationships that make the data operationally meaningful.
Using Geospatial Data Labeling to Improve Spatial Signal Quality
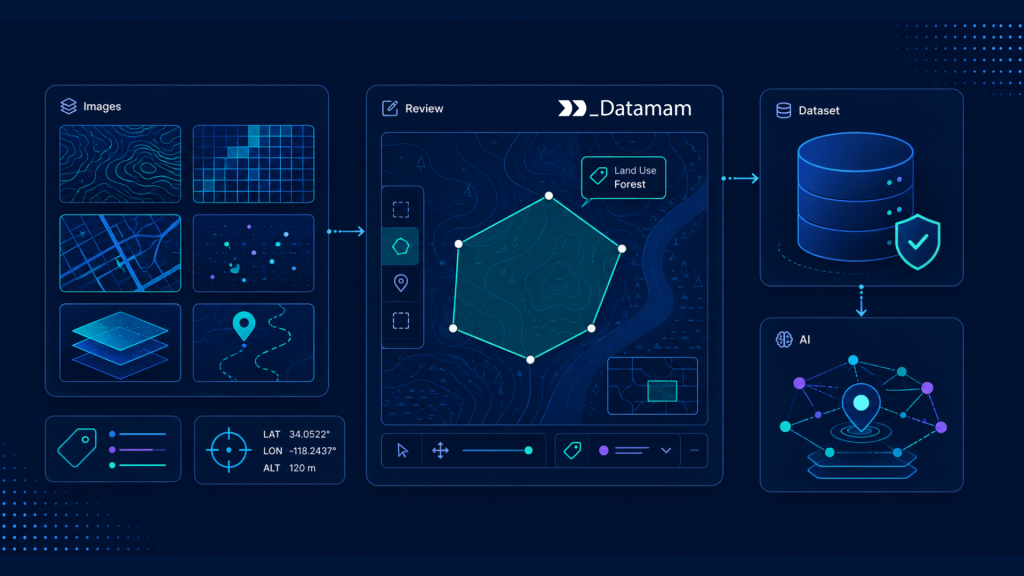
Geospatial data labeling turns raw spatial inputs into machine-readable training signals. Depending on the use case, labeling may involve road segmentation, building footprint extraction, land-cover classification, POI categorization, address matching, lane detection, parcel boundary review, or object detection in satellite and street-level imagery.
High-quality geospatial data labeling requires clear taxonomies, reviewer guidelines, spatial quality checks, and escalation workflows. For example, labeling a road network requires more than identifying visible pavement. Teams may need to mark road class, direction, restrictions, surface type, connectivity, access constraints, and temporal status. These details directly affect routing, logistics, infrastructure monitoring, and location intelligence models.
External Data Requirements for Location Intelligence Data
Location intelligence data often comes from many external sources, including satellite imagery, aerial imagery, mobile movement data, public records, transportation networks, land registries, business listings, weather feeds, infrastructure databases, and open mapping repositories. The challenge is not simply collecting these sources. It is aligning them into coherent datasets that can support reliable spatial reasoning.
Enterprise teams must evaluate each source by coverage, freshness, licensing terms, spatial resolution, update cadence, privacy implications, and compatibility with existing mapping workflows. Without this discipline, teams may build AI models on location intelligence data that appears rich but contains structural gaps, outdated regions, or inconsistent definitions.
Sourcing Geospatial Data Across Imagery, Maps, POIs, and Sensor Feeds
Geospatial AI datasets may include satellite imagery, aerial photography, LiDAR, street-level imagery, GPS traces, mobility records, POI listings, parcel data, traffic feeds, and environmental observations. Each source provides a different view of the physical world. Satellite imagery captures land surface patterns. Street imagery captures ground-level context. POI data captures human activity. Mobility data captures movement.
Sourcing must be documented carefully because each data type has different licensing, privacy, quality, and geographic coverage considerations. Without source-level documentation, teams may struggle to explain why a model performs differently across markets or whether certain data can be used in commercial products.
Normalizing Coordinates, Metadata, and Spatial Resolution
Geospatial data cannot be compared reliably until coordinates, projections, metadata, and spatial resolution are normalized. Different datasets may use different coordinate reference systems, tile schemes, timestamps, resolutions, address formats, region definitions, and category structures. Normalization aligns these inputs into a consistent analytical framework.
For example, a building footprint dataset may need to be aligned with satellite imagery, parcel boundaries, address points, and road networks. If the coordinate system or timestamp is inconsistent, the labels may be spatially shifted, outdated, or mismatched. For mapping training data, small alignment errors can become meaningful model errors.
Managing Data Diversity Across Geography and Use Cases
Different location AI applications require different forms of diversity. A disaster response model may need flood-prone regions, coastal zones, wildfire areas, and post-event imagery. A logistics routing model may need road restrictions, delivery access points, curbside features, and industrial zones. A retail site selection model may need foot traffic, POIs, demographics, and competitive locations.
Accordingly, dataset coverage must be measured by use case. Location intelligence data should be profiled across geography, urban density, sensor type, seasonality, infrastructure conditions, and socioeconomic context. This helps teams identify whether their data supports the model’s intended operating environment or only a narrow subset of it.
Infrastructure Requirements for Geospatial Training Data Pipelines
Geospatial data pipelines must manage large files, spatial indexes, geometry operations, imagery tiles, metadata enrichment, annotation workflows, and reproducible model training. The pipeline must also support versioning because model performance can change when imagery, map layers, labels, or coordinate transformations change. USGS 3D Elevation Program demonstrates how national-scale geospatial data initiatives depend on elevation data coverage, quality levels, source documentation, and structured data delivery.
For enterprise AI teams, this principle applies directly. High-value geospatial datasets are not only collected. They are standardized, documented, versioned, validated, and made usable across analytical and operational systems.
Continuous Data Intake for Imagery, Vector Data, and Metadata
Geospatial training pipelines must ingest imagery, vector layers, POIs, movement data, sensor feeds, and metadata in controlled workflows. Intake may involve APIs, cloud storage, GIS exports, public data portals, commercial feeds, or internal mapping systems. Orchestration tools such as Airflow can manage recurring jobs, retries, dependencies, and validation tasks.
At scale, continuous intake helps teams keep mapping training data current. This is especially important when roads change, construction modifies access, POIs open or close, land use shifts, imagery refreshes, or environmental conditions affect model interpretation.
Validation Controls for Spatial Accuracy and Label Completeness
Validation controls prevent inaccurate spatial data from entering training workflows. These checks may include coordinate validity, geometry topology, duplicate detection, missing metadata, spatial alignment, tile completeness, label coverage, and anomaly detection. For example, a building footprint that appears outside parcel boundaries may require review. A road segment that does not connect to the network may create routing errors.
Geospatial data labeling also requires validation against human review standards. Label consistency, reviewer agreement, and spatial precision should be measured before the dataset is released into model training. Otherwise, models may learn from errors that appear small at the data layer but become costly in production.
Versioning, Lineage, and Reproducibility for Mapping AI
Mapping AI development requires clear lineage across source data, label versions, transformation logic, and model training splits. A model trained on one imagery date may produce different results from a model trained on a later imagery refresh. A revised POI taxonomy may also change model outputs. Without versioning, teams cannot reliably explain performance changes.
Versioning should track source date, coordinate system, transformation code, annotation batch, reviewer workflow, validation status, and train-validation-test split. This allows teams to reproduce model results and evaluate whether performance differences come from model changes, data updates, or labeling changes.
Technology Stack Behind Geospatial Training Data Systems
A mature geospatial training data system operates across data collection, spatial processing, labeling, storage, governance, and model integration. It must handle raster imagery, vector geometries, large metadata tables, spatial joins, time-series data, and annotation outputs. The stack must support both GIS workflows and machine learning workflows because mapping AI depends on spatial correctness as much as statistical performance.
In practice, enterprise mapping teams need infrastructure that connects GIS systems, data lakes, labeling platforms, quality monitoring, and ML pipelines. Without that connection, data scientists inherit fragmented spatial layers while operations teams continue correcting map errors manually.
Collection and Orchestration Using Airflow, APIs, and Controlled Intake Pipelines
Collection workflows may use APIs, secure file transfer, cloud object storage, GIS exports, and controlled ingestion from commercial or public geospatial sources. Apache Airflow can orchestrate recurring intake, schema checks, coordinate validation, tile generation, and data routing into annotation or processing environments.
For dynamic web sources such as public infrastructure portals, planning databases, or government registries, Playwright can support controlled extraction where APIs are unavailable. Kafka can support streaming ingestion when movement signals, sensor data, or map updates need near-real-time processing. Together, these tools support a repeatable intake system rather than ad hoc spatial data gathering.
Processing and Transformation Through Spark, dbt, and Spatial ETL Workflows
Processing layers transform raw spatial inputs into structured datasets. Spark can process large imagery metadata, mobility records, POI tables, and vector features at scale. Spatial ETL workflows can perform coordinate transformations, tile indexing, geometry simplification, map matching, and feature enrichment. dbt can manage standardized analytical models for metadata, QA reporting, and dataset documentation.
These transformations make Geospatial Training Data usable across model training, GIS analysis, and enterprise reporting. Without processing discipline, data scientists inherit inconsistent spatial layers and spend excessive time repairing inputs before they can evaluate model performance.
Storage, Analytics, and Governance in Databricks, Snowflake, BigQuery, or GIS Platforms
Geospatial AI datasets often require object storage for imagery tiles and analytical storage for metadata, features, labels, and audit records. Databricks, Snowflake, BigQuery, and GIS platforms can support spatial queries, dataset profiling, annotation analytics, and model development workflows.
Governance controls should include role-based access, audit logs, data lineage, source licensing documentation, retention rules, and geographic access restrictions. These controls matter because location intelligence data can reveal sensitive patterns about infrastructure, movement, property, or communities. Governance converts spatial data from a collection of files into a controlled enterprise asset.
Commercial Impact of High-Quality Geospatial Training Data
The commercial value of Geospatial Training Data appears when better datasets improve model generalization, reduce manual correction, and accelerate location AI deployment. Mapping products often fail commercially when users encounter incomplete roads, incorrect POIs, outdated entrances, inaccurate boundaries, or unreliable coverage in specific regions. Strong training data infrastructure reduces these issues by improving spatial coverage, label quality, and update reliability.
Better data does not guarantee mapping AI success, but weak data almost always increases rework, review burden, and operational risk. The difference becomes visible in launch readiness, regional expansion, map quality, and user trust.
Improving Model Generalization Across Regions and Spatial Conditions
Generalization is essential for location AI. A model that detects buildings accurately in one country may underperform in another because roof materials, settlement patterns, image resolution, and construction density differ. A road detection model may fail in rural areas, informal settlements, forested regions, or snow-covered environments.
Representative geospatial training data helps models learn patterns that remain stable across diverse physical conditions. Conservative impact typically appears as fewer regional retraining cycles, stronger rollout readiness, better quality review prioritization, and reduced manual correction after deployment.
Reducing Manual Review and Map Correction Workload
Manual map review is expensive and slow. Teams may need to inspect roads, POIs, boundaries, land-use classes, and imagery-derived features repeatedly when model outputs are unreliable. Better geospatial data labeling reduces downstream correction by improving the signal quality used during training.
Clear annotation rules, validation checks, reviewer workflows, and QA dashboards help reduce disagreement and rework. As a result, mapping teams can shift more effort toward edge cases, new geographies, and high-value quality improvements rather than repeatedly fixing preventable labeling errors.
Supporting Faster Deployment of Location Intelligence Products
Location intelligence products often depend on timely spatial updates. Retail site analytics, logistics optimization, insurance risk scoring, infrastructure monitoring, and urban planning tools lose value when location data is stale or inconsistent. Structured training data pipelines allow teams to update datasets, retrain models, validate outputs, and deploy improvements more quickly.
This supports faster market expansion because teams can evaluate new regions, source gaps, data quality issues, and model readiness before launch. In practice, dataset readiness becomes a commercial accelerator.
Risk Exposure When Geospatial Training Data Is Incomplete
Incomplete geospatial training data creates operational, commercial, and governance risk. A navigation model may route vehicles incorrectly. A logistics model may misread delivery access. A land-use model may misclassify industrial zones. A climate risk model may underestimate exposure. These risks often arise not from model architecture but from weak mapping training data, poor labeling, or incomplete coverage.
When spatial AI systems influence operational decisions, data quality becomes a risk control issue. Small errors in location intelligence data can create large downstream consequences when multiplied across delivery routes, underwriting models, infrastructure plans, or site selection systems.
Spatial Bias and Performance Drift Across Regions
Spatial bias occurs when datasets overrepresent certain regions, road types, building styles, income levels, or urban forms. A model may perform better in wealthy urban areas with high-quality imagery and worse in rural or underserved regions. Performance drift can also occur when infrastructure changes, imagery is refreshed, or movement patterns shift.
Teams should monitor model performance across geography, density, infrastructure type, and source quality. Without this monitoring, spatial errors may remain hidden until users or operations teams encounter them in production.
Reliability Gaps from Poor Labeling and Weak Spatial Taxonomies
Poor labeling creates reliability gaps in mapping AI. If road classes are inconsistent, routing models may misinterpret access. If POI categories are too broad, search and recommendation systems may return weak results. Also, if building footprints are misaligned, property analytics may produce inaccurate estimates.
Strong spatial taxonomies are essential. Teams need clear definitions for roads, parcels, POIs, land use, entrances, restrictions, and environmental features. Geospatial data labeling should be treated as a structured quality process, not a generic annotation task.
Compliance and Privacy Risks in Location Intelligence Data
Location intelligence data can be sensitive, especially when it involves movement patterns, property-level details, critical infrastructure, or community-level demographic inference. Governance controls should address privacy, consent, licensing, data minimization, aggregation, and geographic restrictions. These concerns become more significant when datasets cross borders or combine multiple data sources.
Without governance, location AI teams may build powerful systems that are difficult to audit or justify. Traceability and source documentation reduce this risk by showing how data was collected, transformed, labeled, and used.
Governance Requirements for Mapping and Location AI Datasets
Governance must be built into geospatial data pipelines from the beginning. Location data often combines public records, commercial data, imagery, mobile signals, and derived model outputs. Each source may carry different licensing, privacy, and usage constraints. For enterprise AI systems, the same logic applies internally. Spatial data must be managed as a governed asset because it can influence navigation, infrastructure planning, risk scoring, market analysis, and operational decision-making.
Access Controls, Licensing, and Source Documentation
Geospatial datasets should include clear documentation of source, license, permitted use, update cadence, coverage, and quality limitations. Access controls should restrict sensitive imagery, movement data, infrastructure layers, and derived location intelligence outputs. This is especially important when mapping data supports commercial decisions or operational systems.
Source documentation also helps procurement, legal, and compliance teams evaluate whether a dataset can be used for model training, commercial products, internal analytics, or customer-facing applications. Without this documentation, valuable datasets may become difficult to scale responsibly.
Data Lineage Across Training, Validation, and Production Sets
Data lineage allows teams to understand how each spatial feature moved from the source to the model training set. Traceability should cover imagery date, tile ID, coordinate system, label batch, reviewer workflow, transformation code, validation outcome, and dataset split. This matters because leakage between training and validation data can inflate performance metrics.
Lineage also supports production monitoring. If a model fails in a region, teams can review whether the issue originated from source coverage, annotation rules, transformation logic, or model behavior. This makes spatial quality incidents easier to investigate and resolve.
Cross-Border Data Considerations in Location AI Development
Cross-border geospatial data use introduces additional governance complexity. Countries may apply different rules to high-resolution imagery, mapping data, critical infrastructure, mobility records, or personal location data. A dataset that is usable in one jurisdiction may require additional review in another.
For global mapping products, cross-border controls should document data source rights, storage location, access permissions, export limitations, and regional restrictions. This reduces the risk that location intelligence data becomes commercially useful but legally or operationally constrained.
Evaluating Geospatial Training Data Readiness
Geospatial Training Data becomes valuable when it is ready for repeatable model development, not merely when it exists in storage. Readiness depends on geographic coverage, labeling quality, metadata completeness, spatial alignment, governance, and integration with ML workflows. Mapping AI teams should evaluate whether their datasets represent target markets, whether labels match the intended task, and whether lineage supports reproducibility.
A readiness review helps identify dataset gaps before they become model failures, launch delays, or customer-facing map quality issues. It also clarifies whether current mapping training data can support regional expansion, new product use cases, or higher automation levels.
How Mapping AI Teams Assess Dataset Coverage and Quality
A structured assessment should evaluate imagery resolution, geographic diversity, urban-rural balance, coordinate accuracy, label completeness, source freshness, class distribution, and edge-case coverage. It should also measure reviewer agreement, annotation consistency, duplicate rates, missing metadata, and spatial alignment errors.
For mapping training data, quality must be evaluated spatially. A dataset may have millions of labeled objects while still missing critical rural roads, new developments, informal settlements, construction zones, or region-specific POI categories.
When Organizations Need a Geospatial Dataset Architecture Review
A dataset architecture review becomes useful when teams rely on fragmented imagery exports, inconsistent POI feeds, manual labeling spreadsheets, unclear dataset versions, or disconnected GIS and ML workflows. The review should assess intake systems, labeling operations, validation controls, storage architecture, lineage tracking, governance posture, and model integration readiness.
The output should clarify where dataset risk accumulates, where geospatial data labeling may limit model performance, and which infrastructure improvements would make location intelligence data more reliable for mapping AI development.
Conclusion: Geospatial Training Data as Mapping AI Infrastructure
Mapping and location AI systems depend on geospatial data infrastructure as much as model sophistication. Geospatial Training Data must be representative, labeled, normalized, validated, versioned, and governed before it can reliably support spatial AI. Geospatial data labeling provides the spatial signal. Mapping training data provides operational context. Location intelligence data provides the scale and market relevance needed for commercial deployment.
Ultimately, organizations that treat geospatial datasets as governed AI infrastructure will be better positioned to build mapping systems that are accurate, scalable, explainable, and commercially useful across regions.


