Key Takeaways
- Consensus Labeling improves enterprise AI data by requiring structured agreement across reviewers before labels become part of training or evaluation datasets.
- Inter annotator agreement helps teams measure whether reviewers apply labeling rules consistently across categories, edge cases, and business domains.
- Data labeling accuracy depends on expert review, gold standard checks, clear guidelines, reviewer calibration, and controlled dispute resolution.
- Label quality control prevents conflicting, ambiguous, or low-confidence labels from silently entering ground truth datasets.
- Reliable consensus workflows require metadata, lineage, audit logs, reviewer permissions, versioning, and governance across the full AI data lifecycle.
Enterprise AI systems depend on labels that are consistent enough to define what correct means. A single reviewer may label a record quickly, but one reviewer’s judgment is not always enough for high-impact AI data. Ambiguous records, subjective categories, domain-specific edge cases, and inconsistent reviewer interpretation can introduce label noise that weakens model training and evaluation.
Consensus Labeling provides a controlled way to improve label reliability by requiring agreement, review, adjudication, or expert approval before labels become trusted reference data. In enterprise AI workflows, consensus is not only a quality assurance technique. It is a governance mechanism for deciding when labeled data is reliable enough to train models, evaluate outputs, support monitoring, or approve deployment.
Without consensus controls, organizations may scale annotation volume while quietly reducing the quality of the ground truth layer on which their AI systems depend.
Why Consensus Labeling Matters in Enterprise AI Systems
Enterprise AI systems frequently use data that requires human judgment. Customer conversations, product records, legal documents, claims, reviews, market signals, medical text, compliance events, and multimodal content often contain ambiguity. Different reviewers may interpret the same record differently unless the workflow defines how agreement is measured and how disagreements are resolved.
Consensus Labeling matters because enterprise AI data must be repeatable, reviewable, and defensible. IBM’s explanation of human-in-the-loop AI describes human participation as a way to improve model accuracy and provide safeguards when AI systems encounter ambiguity, bias, or edge cases. Consensus labeling operationalizes that human role by converting individual reviews into controlled agreement.
Why AI Data Requires More Than Single-Reviewer Labels
Single-reviewer labeling can work for simple, low-risk tasks with clear definitions. However, many enterprise AI workflows involve categories that are interpretive, domain-specific, or high-impact. A support ticket may contain multiple intents. A product listing may represent a bundle, variant, or duplicate. A compliance document may contain nuanced obligations. A market signal may be a true competitor action or source noise.
In these situations, a single label may reflect one reviewer’s interpretation rather than a stable ground truth decision. If that label enters the training set without review, the model learns from potentially inconsistent judgment. If it enters an evaluation set, model performance metrics may become unreliable.
Consensus workflows reduce this risk by adding a second review, agreement thresholds, expert adjudication, or escalation logic. They help distinguish confident labels from disputed labels before the data influences model behavior.
How Consensus Labeling Improves Trust in Ground Truth Datasets
Ground truth datasets are only useful when teams trust the labels. Consensus Labeling strengthens that trust by showing that labels were not applied arbitrarily. It preserves evidence that reviewers agreed, disagreements were resolved, and final labels met defined quality thresholds.
This is especially important for datasets used in model evaluation or deployment approval. If a test set contains labels that only one reviewer assigned, stakeholders may question whether poor model performance reflects model weakness or label ambiguity. If labels were reviewed through consensus, the evaluation results would become more defensible.
A 2026 research paper on inter-annotator agreement for human annotation notes that as annotation and evaluation tasks expand into subjective judgments, segmentation, and continuous ratings, agreement measurement becomes more complex. For enterprise AI operations, this reinforces the need for structured consensus design rather than informal reviewer agreement.
Operational Problems Created by Weak Label Agreement
Weak label agreement creates unstable AI data. The same record may receive different labels depending on the reviewer, region, guideline interpretation, or review timing. This inconsistency weakens model learning, evaluation, monitoring, and governance.
The problem is often hidden. A dataset may look complete because every record has a label. However, label completeness does not mean label reliability. If reviewers disagree frequently, the dataset may contain noise even when it appears ready for training.
When Annotators Interpret the Same Record Differently
Annotators interpret records differently when labeling rules are vague, categories overlap, examples are missing, or the task requires domain expertise. One reviewer may classify a customer message as a billing complaint, while another classifies it as a cancellation request. One reviewer may treat a product change as a new launch, while another treats it as an assortment update.
These differences are not always reviewer errors. Sometimes they reveal weaknesses in the taxonomy or guidelines. If a record can plausibly belong to two categories, the consensus workflow should expose that ambiguity rather than force silent consistency.
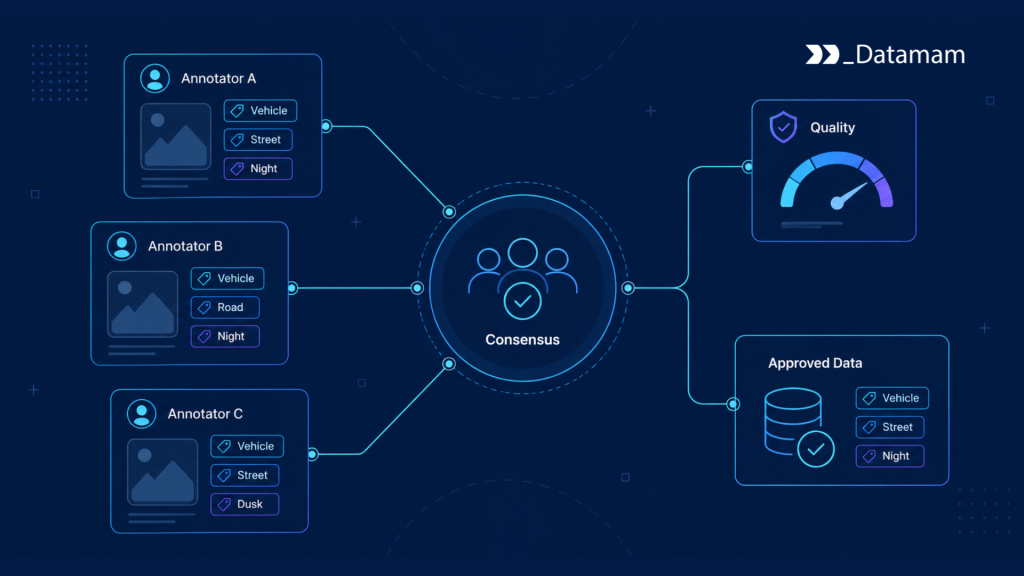
Consensus Labeling creates an operational path for these cases. The workflow may require multiple reviewers, compare labels, calculate agreement, route disagreements to expert adjudication, and update guidelines when recurring disagreements appear.
How Low Inter-Annotator Agreement Weakens Model Training and Evaluation
Low inter-annotator agreement indicates that reviewers are not applying labels consistently. This may mean the task is too subjective, the taxonomy is unstable, the guidelines are unclear, or reviewers need calibration. Whatever the cause, low agreement weakens the AI dataset.
For training, inconsistent labels create conflicting examples. The model learns noise instead of reliable patterns. For evaluation, inconsistent labels distort performance measurement. A model may be penalized for disagreeing with a label that another qualified reviewer would not have applied. For monitoring, low agreement makes it difficult to determine whether production errors reflect model failure or label ambiguity.
NIST’s current AI Risk Management Framework emphasizes governance and risk management across the AI lifecycle. In enterprise data labeling, inter-annotator agreement is one practical signal for whether the ground truth layer is governed well enough to support reliable AI decisions.
Designing Consensus Labeling Workflows for Enterprise AI Data
Consensus labeling workflows define when multiple reviewers are required, how agreement is calculated, which records require adjudication, and when labels become approved for training or evaluation. The workflow should be designed around risk, ambiguity, label complexity, and dataset purpose.
Not every record requires the same review depth. A routine example in a low-risk category may only need one reviewer and sampling-based QA. A high-risk example used in a gold standard dataset may require multiple reviewers, domain expert approval, and a full audit history.
Defining When Multiple Reviewers Are Required
Multiple reviewers should be required when the label is high impact, ambiguous, subjective, newly introduced, or used in evaluation benchmarks. Examples include regulated categories, compliance determinations, customer-sensitive classifications, medical or legal annotation, complex entity matching, and difficult market intelligence signals.
The workflow should define review thresholds. A low-risk label may require one reviewer plus random quality checks. A medium-risk label may require two reviewers and agreement. A high-risk label may require consensus plus expert adjudication. Gold standard records may require senior review and locked approval.
This tiered approach helps control cost while protecting quality. Consensus Labeling does not mean every record receives maximum review. It means review depth matches operational risk.
Structuring Reviewer Roles, Escalation Paths, and Adjudication Logic
Reviewer roles should be explicit. Standard annotators may handle routine records. Senior reviewers may resolve disagreements. Domain experts may adjudicate difficult or high-impact cases. Governance owners may approve final dataset versions or guideline changes.
Escalation paths define what happens when reviewers disagree. The system may route the record to a third reviewer, trigger expert adjudication, classify the record as ambiguous, or exclude it from training. Adjudication logic should preserve the original labels, reviewer confidence, final decision, and rationale.
This matters because the disagreement itself is informative. It may reveal an edge case, weak guideline, unstable taxonomy, or genuinely ambiguous record. A mature workflow does not hide disagreement. It captures it and uses it to improve label quality control.
Separating Routine Labels from High-Risk or Ambiguous Records
Consensus workflows should separate routine records from high-risk or ambiguous records. Routine records can move efficiently through standard annotation and sampling-based QA. High-risk records require stronger review. Ambiguous records require structured handling so they do not pollute training data or distort evaluation sets.
This separation improves both efficiency and quality. Reviewers do not spend unnecessary time on obvious cases, while expert attention is reserved for cases where judgment matters most. It also allows dataset builders to decide how different label types should be used. Confident consensus labels may enter training or testing. Ambiguous labels may be reserved for analysis, excluded, or used in specialized robustness evaluations.
In enterprise AI data operations, this distinction protects model reliability without making annotation workflows unnecessarily slow.
Inter Annotator Agreement as a Quality Signal
Inter-annotator agreement measures how consistently different reviewers apply labels to the same data. It is not a perfect measure of correctness, but it is one of the most useful signals for evaluating whether a labeling task is well-defined and whether reviewers are aligned.
Agreement should be evaluated across categories, reviewer groups, source types, languages, markets, and edge cases. A high overall agreement score may hide low agreement in specific categories that matter most operationally.
Measuring Agreement Across Reviewers, Categories, and Edge Cases
Agreement can be measured through simple percent agreement or more formal metrics, depending on the task. For enterprise workflows, the exact metric matters less than whether the organization uses agreement consistently to improve label quality. Teams should measure where reviewers agree, where they disagree, and which categories produce the most instability.
Category-level agreement is important because some labels are easier than others. A sentiment model may show high agreement for clearly positive reviews but low agreement for mixed or neutral comments. A compliance classifier may show high agreement on obvious violations but low agreement on borderline cases. A product matching workflow may show strong agreement for exact matches and weak agreement for bundles or variants.
Edge-case agreement deserves special attention. These cases often define production risk. If reviewers cannot agree on them, the model is unlikely to behave reliably in production.
Using Agreement Scores to Identify Weak Guidelines and Unstable Labels
Agreement scores should feed back into the labeling system. Low agreement may indicate unclear label definitions, overlapping categories, missing examples, inconsistent reviewer training, or data quality problems. Instead of treating disagreement as a reviewer failure, teams should investigate the cause.
If two labels are frequently confused, the taxonomy may need clearer boundaries. If one reviewer consistently disagrees with others, reviewer calibration may be needed. Also, if all reviewers disagree on a category, the label itself may be unstable. If agreement drops after a guideline change, the change may have introduced ambiguity.
This turns inter-annotator agreement into an operational diagnostic. It helps teams improve the data labeling workflow before label noise reaches model training.
Connecting Agreement Metrics to Dataset Approval Decisions
Agreement metrics should influence dataset approval. A dataset should not automatically move into training, evaluation, or deployment review because labeling is complete. It should meet quality thresholds appropriate for its use.
Training datasets may tolerate some ambiguity if the labels are useful and reviewed. Test sets, gold standard datasets, and high-impact evaluation sets require stricter agreement. Production monitoring sets may require agreement thresholds by category, so performance metrics are not distorted by unstable labels.
Gartner’s 2025 research on the data and analytics governance reset with AI states that generative AI and the need to govern unstructured data are straining governance efforts. Agreement metrics are a practical governance control because they provide measurable evidence of label reliability.
Data Labeling Accuracy and Review Controls
Data labeling accuracy depends on more than reviewer effort. It requires clear definitions, gold standard checks, expert review, reviewer calibration, and controlled dispute resolution. Accuracy must be measured and managed continuously because labeling tasks evolve as data changes.
In enterprise AI workflows, accuracy controls must be connected to dataset roles. A label used for exploratory training may not require the same evidence as a label used in a benchmark or deployment approval set.
Validating Label Accuracy Through Expert Review and Gold Standard Checks
Expert review helps validate labels where domain judgment matters. A general reviewer may classify routine records, but expert reviewers should validate difficult labels, high-impact categories, and records used in gold standard datasets.
Gold standard checks compare reviewer labels against trusted benchmark examples. These checks can identify reviewer drift, guideline misunderstanding, and category confusion. They also provide a controlled way to measure labeling accuracy across teams and time.
This is especially important when annotation is distributed across multiple reviewers, vendors, regions, or languages. Gold standard checks establish a shared quality reference so label quality does not depend only on informal supervision.
Detecting Reviewer Drift, Label Bias, and Inconsistent Decision Patterns
Reviewer drift occurs when annotators gradually change how they apply labels. This may happen after repeated exposure to similar records, ambiguous guidelines, fatigue, or changes in source data. Label bias occurs when reviewers systematically favor one category, interpretation, or assumption.
Inconsistent decision patterns can be detected by monitoring reviewer-level agreement, category distribution, confidence scores, correction rates, and expert override frequency. If one reviewer assigns a label far more often than others, the workflow should investigate whether the pattern reflects expertise, bias, or misunderstanding.
Label quality control should include periodic calibration. Reviewers should revisit guidelines, compare decisions, resolve disagreements, and receive feedback based on gold standard examples.
Managing Disputes, Low-Confidence Labels, and Ambiguous Examples
Disputes should be managed through defined adjudication. When reviewers disagree, the workflow should preserve all submitted labels, confidence scores, comments, and final decisions. The final label should not erase the disagreement history.
Low-confidence labels require careful handling. Some can be included in training with confidence metadata. Others should be excluded from evaluation sets. Ambiguous examples may be useful for stress testing but inappropriate for gold standard benchmarks.
A mature consensus workflow treats uncertainty as metadata. It does not pretend every record has a simple answer. This strengthens data labeling accuracy because downstream teams can distinguish high-confidence labels from unresolved or borderline cases.
Label Quality Control in Enterprise Annotation Systems
Label quality control ensures that only labels meeting defined standards enter trusted datasets. It includes agreement measurement, expert review, quality thresholds, sampling checks, dispute resolution, audit logs, and dataset approval gates.
Enterprise annotation systems need quality control because labeling errors scale quickly. A small percentage of inconsistent labels can distort model behavior, especially in rare classes or high-impact categories.
Creating Quality Thresholds Before Labels Enter Training Data
Quality thresholds should be defined before annotation begins. These may include minimum agreement levels, expert approval requirements, reviewer confidence thresholds, category-specific QA rules, and dispute resolution requirements.
Different datasets require different thresholds. Training data may allow a wider range of reviewed labels. Evaluation data should require stricter confidence and agreement. Gold standard datasets should require the highest level of review and protection from leakage.
Quality thresholds create consistency. They prevent teams from deciding label acceptability informally after the dataset is already built. They also make dataset approval auditable.
Routing Failed, Conflicting, or Uncertain Labels into Review Queues
Labels that fail quality checks should not silently enter production datasets. They should be routed into review queues with sufficient context for resolution. This may include original record data, reviewer labels, confidence scores, guideline version, disagreement type, and related examples.
Conflicting labels may need adjudication. Failed gold standard checks may require reviewer calibration. Uncertain labels may require expert review or exclusion. Repeated failures in one category may trigger taxonomy or guideline updates.
Review queues turn label quality control into a continuous improvement process. They prevent bad labels from becoming hidden training noise and help teams identify systemic issues in the labeling workflow.
Preserving Label History, Reviewer Confidence, and Final Decisions
Label history should be preserved. If a record was labeled as one category, disputed, reviewed, and changed, the system should retain the full path. This history helps teams understand why a final decision was made and whether similar examples should be handled the same way.
Reviewer confidence is also important. A label with strong consensus and high confidence should be treated differently from a label accepted after difficult adjudication. Final decisions should include rationale where appropriate, especially for high-risk labels.
Audit trails make label quality control defensible. If model behavior is questioned, teams can inspect the labels that shaped it.
Technology Stack Behind Consensus Labeling
Consensus labeling requires infrastructure that supports multi-reviewer workflows, label comparison, agreement metrics, adjudication, quality control, metadata capture, storage, versioning, and governance. The stack should make label decisions traceable from the raw record to the final approved dataset.
Tools do not replace labeling policy, but they enforce consistency and scale. The goal is to ensure that consensus workflows remain reliable as dataset volume, reviewer count, and model complexity increase.
Orchestration, Storage, and Processing for Multi-Reviewer Workflows
Airflow can orchestrate annotation batches, reviewer assignment, second-review triggers, adjudication queues, quality checks, and dataset publication. Kafka can route new production errors, uncertain examples, or active learning selections into review workflows. Spark can process large labeled datasets to calculate agreement, detect distribution issues, and identify disagreement patterns at scale.
Storage platforms such as Snowflake, BigQuery, and Databricks can preserve raw records, reviewer labels, consensus decisions, quality metrics, gold standard checks, and dataset versions. These systems allow AI, data, and governance teams to query label quality across categories, reviewers, and time periods.
This infrastructure makes consensus labeling operational rather than manual. It supports repeatable review and controlled dataset release.
Metadata, Lineage, and Versioning Across Label Review Stages
Metadata should capture source origin, assigned reviewers, submitted labels, confidence scores, guideline version, agreement status, adjudication outcome, final label, dataset role, and dataset version. Lineage should connect source records to reviewer decisions, consensus labels, training datasets, evaluation sets, and model versions.
Versioning is essential because labels and guidelines change. A final label should be tied to the guideline version used at the time of review. If a taxonomy changes, teams need to know which labels may need re-review and which model evaluations used older definitions.
Without metadata, lineage, and versioning, consensus decisions become difficult to audit. The dataset may appear approved, but teams cannot reconstruct why labels were accepted.
Observability, Audit Logs, and Governance Controls for Label Quality
Observability tools such as Prometheus can monitor annotation throughput, review backlog, agreement rates, dispute volume, expert review latency, gold standard pass rates, and label distribution changes. Validation frameworks can check whether approved datasets meet required quality thresholds before publication.
Audit logs should preserve reviewer actions, label changes, adjudication decisions, approvals, guideline updates, and dataset publication events. Governance controls should define who can label, review, adjudicate, approve, and modify consensus rules.
OECD’s 2025 Digital Government Index and Open, Useful and Re-usable Data Index emphasizes coherent data foundations and reusable data policies. Enterprise consensus labeling follows the same principle: AI data becomes more reliable when label decisions are structured, reusable, traceable, and governed.
Governance and Compliance in Consensus Labeling
Consensus labeling governance defines who can review data, how agreement is measured, when disputes are escalated, which thresholds apply, and when labeled data is approved for use. Governance is especially important when labels affect regulated, sensitive, customer-facing, or high-impact AI systems.
The governance objective is not to slow annotation. It is to ensure that label quality can be explained and defended.
Managing Reviewer Permissions, Access Controls, and Source Accountability
Reviewer permissions should reflect expertise, sensitivity, and role. Some reviewers may handle routine labels. Others may be authorized for expert adjudication. Sensitive datasets may require restricted access. High-impact categories may require additional approval.
Access controls are necessary when annotation data includes customer records, proprietary documents, regulated information, market-sensitive data, or restricted source material. The labeling system should preserve who accessed and labeled each record.
Source accountability also matters. Reviewers need to know enough source context to make accurate labeling decisions, but sensitive or restricted source data must be controlled. Governance metadata should preserve source origin, usage conditions, and any restrictions attached to the record.
Supporting Audit Readiness for AI Data Labeling Decisions
Audit readiness requires evidence that labeling decisions were controlled. Teams should be able to show who labeled a record, whether reviewers agreed, how disagreements were resolved, which guideline version applied, whether the final label passed quality thresholds, and which dataset version used the label.
This evidence matters when AI outputs are questioned. If a model makes an incorrect classification, teams need to determine whether the problem came from model behavior, label ambiguity, reviewer disagreement, taxonomy design, or source data quality.
Consensus Labeling provides the evidence layer behind AI data. It allows governance teams, procurement evaluators, compliance stakeholders, and AI leaders to inspect how ground truth was created.
You can run an external data infrastructure audit with our team to review your current setup and understand what is required to build a reliable, enterprise-scale external data infrastructure.
Consensus Labeling as AI Data Infrastructure
Consensus labeling becomes AI data infrastructure when it operates continuously across dataset creation, evaluation, monitoring, and retraining. It is not a one-time quality check. It is the process by which an enterprise decides which labels are trustworthy enough to influence model behavior.
As AI systems evolve, new edge cases appear, reviewers encounter new ambiguity, and business definitions change. Consensus workflows provide a way to adapt without losing control over label quality.
Strengthening Ground Truth Quality, Model Evaluation, and Retraining Decisions
Ground truth quality improves when labels are reviewed, agreed upon, and documented. Model evaluation becomes more reliable when benchmark datasets contain consensus-approved labels. Retraining decisions become stronger when production errors are reviewed through the same consensus workflow used to create training data.
For example, if a model repeatedly misclassifies a category, the organization should not immediately assume the model is wrong. It should inspect whether consensus exists on the label. If reviewers disagree, the problem may be taxonomy ambiguity rather than model failure. If reviewers agree, the record may be a useful retraining example.
Consensus workflows help teams make that distinction. They improve both model quality and diagnostic accuracy.
Building Long-Term Trust in Enterprise AI Data Operations
Long-term trust depends on consistent label governance. Business users need confidence that AI outputs are trained on reliable data. AI teams need confidence that evaluation benchmarks are stable. Governance teams need evidence that labels were reviewed properly. Executives need confidence that AI systems are not built on arbitrary human judgment.
Consensus Labeling supports that trust by preserving reviewer agreement, label quality control, data labeling accuracy checks, and audit trails. It gives the organization a repeatable process for deciding when labeled data is ready for use.
Ultimately, enterprise AI data operations become more reliable when label quality is treated as infrastructure, not annotation administration.
Conclusion: Turning Reviewer Agreement into Reliable AI Training Data
Enterprise AI systems require labels that are accurate, consistent, reviewable, and defensible. Single-reviewer labels may be sufficient for simple tasks, but complex enterprise AI data requires stronger controls. Ambiguous records, high-impact categories, subjective judgments, and domain-specific examples need structured agreement.
Consensus Labeling provides that control layer. It uses inter-annotator agreement, data labeling accuracy checks, label quality control, adjudication, metadata, lineage, audit logs, and governance to improve the reliability of AI training and evaluation data.
The capability matters because models learn from labels. If labels are inconsistent, models learn uncertainty as if it were truth. If labels are reviewed through consensus, AI systems gain a stronger foundation for training, evaluation, monitoring, and retraining.
A structured review can help evaluate whether current AI data workflows have reliable consensus labeling controls, reviewer agreement metrics, label quality thresholds, adjudication workflows, versioned datasets, and audit-ready annotation records. You can run an external data infrastructure audit with our team to review your current setup and understand what is required to build a reliable, enterprise-scale external data infrastructure.


