Key Takeaways
- Label Taxonomy gives enterprise AI systems a structured vocabulary for training, evaluation, monitoring, and model governance.
- Data labeling taxonomy design must define label boundaries, decision criteria, exclusions, edge cases, and business meaning before annotation begins.
- Label hierarchy design helps teams organize parent categories, subcategories, and domain-specific labels without creating confusion for annotators or models.
- A taxonomy management system is required to version label definitions, approve changes, track ownership, and connect taxonomy updates to datasets and model performance.
- Reliable label taxonomy design requires metadata, lineage, audit logs, reviewer agreement checks, and governance controls across the full AI data lifecycle.
Enterprise AI systems depend on labels that translate business meaning into machine-readable structure. A model cannot reliably classify records, detect intent, identify market signals, group documents, interpret customer feedback, or evaluate outputs if the label system underneath it is unclear.
Label Taxonomy is the controlled structure that defines which labels exist, what each label means, how labels relate to one another, and when each label should or should not be applied. In enterprise AI workflows, label taxonomy design affects training data quality, annotation consistency, model evaluation, production monitoring, and governance review.
The risk is not only having inaccurate labels. The bigger risk is having labels that overlap, drift, conflict, or fail to represent the operational reality the model is expected to learn. When label definitions are unstable, AI systems inherit that instability.
Why Label Taxonomy Matters in Enterprise AI Systems
Enterprise AI systems increasingly depend on large volumes of structured, semi-structured, and unstructured data. Customer conversations, product records, legal documents, market signals, images, reviews, support tickets, compliance events, and operational logs all require classification before they can become useful training data.
Label Taxonomy provides the classification logic. It defines the categories that annotators use, the categories that models learn, and the categories that performance metrics measure. As Gartner’s 2025 data and analytics governance research notes, the rise of generative AI and the need to govern unstructured data are straining traditional governance operating models. Label taxonomy is one of the practical controls required to bring structure to that unstructured AI data environment.
Why AI Models Need Structured Label Definitions
AI models need labels that represent consistent decisions. A classification model learns from repeated examples. If the same type of record is labeled differently across annotators, markets, or review cycles, the model receives conflicting instructions. The issue is not just annotation error. It is structural ambiguity.
Structured label definitions reduce that ambiguity. Each label should define scope, inclusion criteria, exclusion criteria, edge cases, examples, counterexamples, and escalation rules. For instance, a customer feedback classifier should distinguish product defect, delivery issue, pricing complaint, usability problem, and irrelevant comment. A market intelligence classifier should distinguish competitor launch, promotion, stockout, assortment change, and source noise.
Without clear definitions, labels become subjective. A model trained on subjective labels may produce outputs that look mathematically confident but remain operationally unreliable.
How Weak Label Taxonomies Create Model Confusion and Evaluation Risk
Weak label taxonomies confuse both annotators and models. If categories overlap, annotators apply labels inconsistently. If categories are too broad, important distinctions disappear. Also, if categories are too narrow, examples become sparse and hard for the model to learn. If labels do not reflect business reality, model outputs become difficult to use in production.
Evaluation risk follows. A model may appear accurate because the evaluation set uses vague labels. Another model may appear weak because the taxonomy is too granular for available data. In both cases, performance metrics are shaped by taxonomy design as much as model quality.
NIST’s AI Risk Management Framework emphasizes governance and risk management across AI systems. In practice, label taxonomy design is part of that risk control layer because it defines what “correct” means before the model is trained or evaluated.
Operational Problems Created by Poor Label Taxonomy Design
Poor label taxonomy design creates problems that spread across the AI lifecycle. Annotation teams disagree. Model teams receive noisy training data. Evaluation metrics become unstable. Production users lose confidence in model outputs. Governance teams struggle to explain how decisions were categorized.
These issues often emerge late because the taxonomy may appear complete on paper. The problem becomes visible only when real records do not fit cleanly into the label structure.
When Labels Overlap, Conflict, or Fail to Reflect Business Reality
Overlapping labels create inconsistent annotations. If “product complaint” and “quality issue” are both available without clear boundaries, reviewers may label the same record differently. Conflicting labels create logical errors. If an item can be both “resolved” and “unresolved” without hierarchy or rule logic, downstream interpretation becomes unreliable.
Labels can also fail because they do not reflect how the business actually operates. A taxonomy designed by technical teams alone may miss domain-specific distinctions. A taxonomy designed by business teams alone may create categories that are meaningful to humans but too ambiguous for annotation and model training.
Good label taxonomy design requires collaboration between domain experts, data scientists, annotators, governance teams, and system owners. The goal is to create labels that are meaningful for business interpretation and usable for machine learning.
How Inconsistent Labels Distort Training, Testing, and Production Outputs
Inconsistent labels distort training because the model learns contradictory examples. They distort testing because the evaluation set does not provide a stable benchmark. They distort production because outputs may not align with user expectations.
For example, a model trained to classify support tickets may confuse “refund request” with “billing complaint” if the taxonomy does not define the difference. A market signal model may confuse “new product launch” with “assortment expansion” if labels are not separated clearly. A compliance classifier may fail when labels are based on informal reviewer judgment rather than policy-defined criteria.
IBM’s AI governance implementation guide frames governance as the bridge between technical AI deployment and organizational accountability. Label consistency is part of that accountability because it determines whether training and evaluation data can be trusted at enterprise scale.
Designing a Data Labeling Taxonomy for Enterprise AI Workflows
A data labeling taxonomy should be designed before large-scale annotation begins. Retrofitting taxonomy structure after thousands or millions of records have already been labeled creates rework, inconsistency, and evaluation instability.
The design process should define label purpose, scope, hierarchy, boundaries, business rules, edge-case handling, review workflow, and versioning. The taxonomy should also connect to the downstream AI system it supports. A taxonomy for search relevance is different from a taxonomy for customer support classification, fraud detection, market intelligence, compliance review, or document routing.
Defining Label Scope, Boundaries, and Decision Criteria
Label scope defines what the taxonomy covers. It should make clear whether labels classify intent, topic, sentiment, risk, product type, entity relationship, market event, document type, or operational outcome. Boundaries define what each label includes and excludes.
Decision criteria help annotators apply labels consistently. They should answer questions such as: What evidence is required to apply this label? What happens when two labels seem valid? Which label takes priority? When should a record be marked ambiguous? When should it be excluded?
For example, a “competitor promotion” label may require evidence of a discount, campaign messaging, or promotional timing. A simple price change may not qualify. Without this distinction, the model may learn that any price movement is a promotion, weakening downstream intelligence.
Mapping Business Concepts into Machine-Readable Label Categories
Business teams often describe concepts in broad language. AI systems require operational precision. Label taxonomy design translates business concepts into machine-readable categories that can be applied consistently across records.
A business concept such as “customer dissatisfaction” may need to be split into product quality, pricing issue, delivery delay, service complaint, missing feature, and cancellation intent. A concept such as “market movement” may need to be split into price change, new listing, stockout, competitor launch, regional expansion, and category shift.
This translation requires discipline. Labels should be specific enough to support model learning and business action, but not so granular that each category lacks enough examples. The taxonomy should reflect both analytical usefulness and data availability.
Managing Edge Cases, Ambiguous Records, and Exclusion Rules
Every enterprise taxonomy needs rules for edge cases. Real data rarely fits perfectly into predefined labels. Customer comments may contain multiple issues. Product records may represent bundles or variants. Market signals may be temporary, duplicated, or incomplete. Documents may contain mixed intent.
Ambiguous records should not be forced into confident labels without review. The taxonomy should define when to use ambiguity labels, when to escalate to expert review, when to apply multiple labels, and when to exclude a record from training.
Exclusion rules are especially important. Some records may be unsuitable for training because they are incomplete, low-confidence, duplicated, outdated, or outside the taxonomy’s scope. Clear exclusion criteria protect dataset quality and prevent weak examples from contaminating model learning.
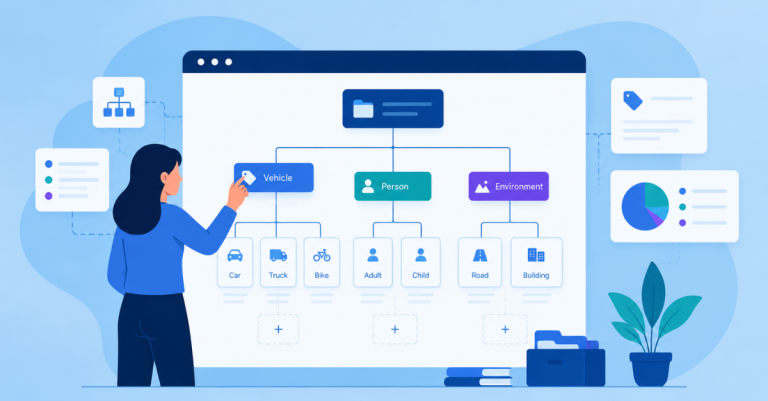
Label Hierarchy Design Across Complex AI Use Cases
Label hierarchy design defines how labels relate to one another. In simple classification tasks, a flat taxonomy may work. In enterprise AI systems, labels often require parent categories, child categories, subcategories, and sometimes multi-label relationships.
The hierarchy must support both human review and model performance. A taxonomy that is intuitive to business users may still be too complex for reliable annotation. A taxonomy that is easy for a model may be too shallow for business use. The design must balance both needs.
Structuring Parent, Child, and Subcategory Relationships
Parent labels provide broad categories. Child labels add specificity. Subcategories capture operational distinctions. For example, a customer support taxonomy may use “billing” as a parent label, with child labels such as invoice issue, refund request, payment failure, subscription cancellation, and pricing dispute.
A market intelligence taxonomy may use “competitor activity” as a parent label, with child labels for price change, product launch, promotion, assortment expansion, and channel entry. This structure supports analysis at different levels. Executives may need parent-level trends, while operational teams need subcategory-level detail.
The hierarchy should prevent logical conflicts. A child label should inherit meaning from the parent. Categories should not overlap without explicit multi-label rules. If the same record can belong to multiple branches, the taxonomy must define how that case is handled.
Balancing Granularity, Usability, and Model Performance
Granularity creates detail, but too much detail can weaken usability and model performance. A taxonomy with hundreds of labels may be difficult for annotators to apply consistently. Sparse categories may not contain enough examples for reliable model training. Excessive granularity can also make evaluation unstable.
By contrast, a taxonomy that is too broad may hide meaningful differences. A general “complaint” label may not provide enough operational insight. A general “competitor update” label may not distinguish launch signals from pricing movement.
The right granularity depends on use case, data volume, label clarity, and decision need. Teams should evaluate whether each label supports a meaningful action, whether annotators can apply it consistently, and whether enough examples exist to train and evaluate the model.
Supporting Multi-Domain, Multi-Market, and Multi-Language Label Structures
Enterprise AI systems often operate across business units, geographies, languages, and data domains. A label taxonomy must be stable enough to support consistency but flexible enough to handle domain-specific variation.
A global taxonomy may define core labels that apply across markets, while allowing regional extensions where necessary. Multi-language taxonomies may require localized examples and definitions while preserving the same underlying category meaning. Multi-domain systems may use shared parent categories with domain-specific child labels.
This structure requires governance. Without a taxonomy management system, regional or domain-specific extensions can grow uncontrolled. Over time, teams may create duplicate labels, conflicting definitions, or categories that cannot be compared across markets.
Taxonomy Management System Requirements
A taxonomy management system controls how label definitions are created, changed, approved, versioned, and connected to datasets and models. It prevents the taxonomy from becoming a static document that quickly falls behind business reality.
Enterprise taxonomies evolve. New products emerge. Policies change. Customer language shifts. Market conditions change. AI use cases expand. The management system must allow controlled evolution without breaking historical comparability.
Versioning Label Definitions as Business Conditions Change
Label definitions change when business rules change or when edge cases reveal weaknesses in the taxonomy. Versioning allows teams to update labels while preserving historical context.
Each taxonomy version should record changed labels, retired labels, new labels, definition updates, hierarchy changes, approval status, effective date, and affected datasets. If a model trained on taxonomy version 1 behaves differently from a model trained on version 2, teams need to understand whether taxonomy changes contributed to that difference.
Version control also supports reproducibility. Model evaluations should be tied to the taxonomy version used during labeling. Without that connection, teams cannot reliably compare results over time.
Tracking Ownership, Review Status, and Approval Workflows
Every label should have an owner. Ownership may sit with a domain expert, data governance lead, AI product owner, compliance reviewer, or taxonomy manager. Ownership ensures that label definitions are reviewed and updated by accountable stakeholders rather than modified informally.
The review status should indicate whether a label is proposed, active, deprecated, retired, or under review. Approval workflows should define who can add labels, change definitions, merge categories, split categories, or retire labels.
This is especially important in regulated or high-impact AI workflows. A label used in compliance review, customer decisioning, financial risk, or public-facing automation should not be changed without proper approval and documentation.
Connecting Taxonomy Changes to Training Data and Model Evaluation
Taxonomy changes affect datasets and models. Adding a new label may require relabeling historical examples. Splitting a category may affect evaluation metrics. Merging labels may simplify training but reduce analytical detail. Retiring a label may affect production monitoring.
A taxonomy management system should connect label changes to training data, validation sets, test sets, model versions, dashboards, and production workflows. This enables pipeline impact analysis. Teams can see which datasets need review and which models may be affected before a taxonomy change is deployed.
This connection turns taxonomy management into operational infrastructure rather than documentation. It allows AI teams to evolve labels without losing control over model behavior.
Quality Controls in Enterprise Label Taxonomies
Label taxonomy quality must be measured. A taxonomy that looks logical in planning may fail during annotation. Reviewers may disagree. Categories may overlap. Some labels may receive too few examples. Others may become dumping grounds for ambiguous records.
Quality controls help teams identify these problems early. They measure whether labels are usable, stable, and aligned with the AI system’s purpose.
Measuring Label Consistency, Reviewer Agreement, and Classification Drift
Reviewer agreement is one of the strongest indicators of taxonomy clarity. If trained reviewers frequently disagree, the issue may be unclear definitions, overlapping categories, insufficient examples, or inadequate guidelines.
Label consistency should also be monitored over time. A label may drift as reviewers encounter new records or business context changes. Classification drift occurs when the meaning or usage of a label shifts without formal taxonomy updates.
Monitoring reviewer agreement, label distribution, confidence scores, and disagreement patterns helps identify weaknesses in the taxonomy. These metrics should feed back into guideline updates, reviewer calibration, and taxonomy refinement.
Detecting Taxonomy Gaps, Duplicate Labels, and Unstable Categories
Taxonomy gaps appear when records do not fit any existing label. Duplicate labels appear when two categories represent similar concepts under different names. Unstable categories appear when usage patterns fluctuate because reviewers interpret them inconsistently.
These issues should be detected through annotation review, exception tracking, distribution analysis, and reviewer feedback. If too many records are marked “other,” the taxonomy may be missing important categories. If a label receives very few examples, it may be too narrow or unnecessary. Also, if two labels are often confused, they may need clearer boundaries or consolidation.
Quality control should treat taxonomy design as iterative. The goal is not to create the perfect taxonomy once. The goal is to maintain a taxonomy that remains useful as data and business conditions change.
Creating Review Loops for New Labels and Retired Categories
New labels should not be added casually. Each proposed label should be evaluated for business value, data availability, annotation clarity, model usefulness, and overlap with existing labels. The review process should also define how historical records will be handled.
Retired categories require similar care. A label may become obsolete because business conditions change, the category is merged, or it lacks enough examples. Retiring a label should preserve historical meaning while preventing future use.
Review loops make taxonomy evolution controlled. They allow the organization to adapt without creating hidden inconsistency in training data and evaluation sets.
Technology Stack Behind Label Taxonomy Design
Enterprise label taxonomy design requires infrastructure that connects annotation workflows, taxonomy management, training datasets, evaluation sets, model versions, and governance systems. The stack should make label definitions accessible, versioned, reviewable, and connected to downstream AI assets.
Tools do not solve taxonomy design by themselves, but they enforce repeatability and traceability.
Orchestration, Storage, and Processing for Taxonomy-Driven Labeling
Airflow can orchestrate labeling workflows, taxonomy updates, dataset refreshes, review queues, and evaluation set publication. Spark can process large-scale labeled datasets, detect duplicate labels, analyze class distributions, and identify taxonomy gaps across high-volume records.
Snowflake, BigQuery, and Databricks can store label definitions, labeled records, taxonomy versions, review status, and model evaluation outputs. These platforms allow teams to analyze how label changes affect dataset composition and model performance.
A mature taxonomy workflow should preserve both the label applied and the taxonomy version used. This prevents historical labels from being interpreted under the wrong definition.
Metadata, Lineage, and Versioning Across Label Workflows
Metadata should include label definition, hierarchy position, owner, approval status, guideline version, reviewer confidence, dataset role, and model use. Lineage should connect labels to source records, annotation decisions, dataset versions, training runs, evaluation metrics, and production outputs.
Versioning should apply to the taxonomy itself and to the datasets created from it. If a category definition changes, downstream users need to know whether previous labels remain valid or require review.
Metadata and lineage make label taxonomy operational. They allow teams to trace how a label moved from business definition to annotation decision to model behavior.
Observability, Audit Logs, and Governance Controls for Taxonomy Management
Observability systems can monitor label distribution, annotation throughput, reviewer disagreement, taxonomy gap rates, and review backlog. Audit logs should preserve taxonomy changes, approval decisions, reviewer actions, label overrides, and dataset publication history.
Governance controls define who can modify labels, approve taxonomy versions, access sensitive categories, or publish labeled datasets. These controls are critical when labels affect high-impact decisions, customer interactions, compliance workflows, or AI automation.
OECD’s 2025 Digital Government Index and Open, Useful and Re-usable Data Index emphasize coherent data foundations and reusable data practices in digital systems. Enterprise label taxonomies require the same discipline because reusable AI data depends on structured, governed categories.
Governance and Compliance in Label Taxonomy Management
Label taxonomy governance defines how labels are created, changed, approved, reviewed, retired, and audited. It also defines how label decisions connect to AI risk management, model evaluation, and production use.
Governance is necessary because labels encode business judgment. When a model classifies a record, it applies the organization’s label structure. If that structure is weak or uncontrolled, the model inherits the weakness.
Managing Access Controls, Review Permissions, and Source Accountability
Not every user should be able to modify taxonomy definitions. Access controls should distinguish taxonomy viewers, annotators, reviewers, approvers, governance owners, and system administrators. Sensitive labels may require restricted access, especially in customer, compliance, legal, health, financial, or employment-related workflows.
Review permissions should reflect domain expertise. A data scientist may identify taxonomy performance issues, but a domain expert may need to approve label meaning. A compliance stakeholder may need to review labels used in regulated processes.
Source accountability also matters. Labels should be tied to the source context where relevant. If a label was applied to customer text, market data, internal documents, or third-party records, teams should understand the source origin and usage constraints.
Supporting Audit Readiness for AI Label Definitions and Dataset Versions
Audit readiness requires evidence. Teams should be able to show which taxonomy version was used, which labels existed, how they were defined, who approved them, how records were labeled, and which datasets or models depended on those labels.
This evidence matters when AI outputs are challenged. If a model incorrectly classifies a record, teams need to know whether the issue came from the model, the annotation, the taxonomy definition, or a source-data problem.
Label taxonomy auditability also supports procurement and enterprise risk review. It demonstrates that AI systems are not trained on arbitrary categories but on governed, reviewable, versioned label structures.
You can run an external data infrastructure audit with our team to review your current setup and understand what is required to build a reliable, enterprise-scale external data infrastructure.
Label Taxonomy as AI Infrastructure
Label Taxonomy becomes an AI infrastructure when it is embedded across data labeling, model training, evaluation, monitoring, and governance workflows. It is not merely a naming convention. It is the decision structure that connects business meaning to model behavior.
At scale, enterprise AI teams need stable labels, reviewable definitions, controlled hierarchy, and clear taxonomy ownership. Without this structure, models may perform inconsistently even when training pipelines and model architectures are technically sound.
Strengthening Training Data Quality, Evaluation Reliability, and Model Monitoring
Training data quality improves when labels are clearly defined and consistently applied. Evaluation reliability improves when test sets are built from stable taxonomy versions. Model monitoring improves when production outputs can be compared against known label structures.
A strong taxonomy also makes failure analysis easier. If a model performs poorly on a category, teams can inspect whether the label is too broad, too narrow, underrepresented, ambiguous, or inconsistently reviewed. This helps teams decide whether to improve the model, revise the taxonomy, relabel data, or collect additional examples.
Label taxonomy, therefore, supports continuous model improvement. It creates a structured feedback loop between production performance and data design.
Building Long-Term Trust in Enterprise AI Classification Systems
Long-term trust depends on label stability and explainability. Business users need to know what model outputs mean. Data teams need to know how labels were defined. Governance teams need to know who approved taxonomy changes. AI teams need to know which taxonomy version was used for training and evaluation.
A taxonomy management system provides that continuity. It helps enterprises evolve labels as business conditions change without losing control over historical comparisons or model performance interpretation.
Ultimately, AI classification systems become more trustworthy when their labels are structured, governed, and traceable. The model’s output is only as meaningful as the taxonomy behind it.
Conclusion: Turning Label Structure into Reliable AI Decision Logic
Enterprise AI systems require more than labeled data. They require a label structure that is clear, governed, reviewable, and aligned with business reality. Label Taxonomy provides that structure.
By designing a strong data labeling taxonomy, managing label hierarchy design, and operating a taxonomy management system, enterprises improve training data quality, evaluation reliability, annotation consistency, and model governance. They also reduce the risk of ambiguous labels, unstable categories, overlapping definitions, and undocumented taxonomy drift.
The capability matters because labels define what the AI system learns and how its outputs are interpreted. If the taxonomy is weak, the model learns from confusion. If the taxonomy is controlled, the model learns from structured business logic.
A structured review can help evaluate whether current AI data workflows have reliable label definitions, taxonomy governance, hierarchy design, reviewer agreement controls, versioning, and audit-ready metadata. You can run an external data infrastructure audit with our team to review your current setup and understand what is required to build a reliable, enterprise-scale external data infrastructure.


