
Key Takeaways
- Active Learning Workflows help enterprise AI teams expand datasets by selecting the most informative records for labeling instead of labeling data passively.
- An active learning pipeline connects model uncertainty, intelligent data sampling, human review, annotation quality, and retraining into one controlled feedback loop.
- A data labeling workflow becomes more efficient when ambiguous, rare, high-impact, and low-confidence records are prioritized for review.
- Intelligent data sampling reduces redundant labeling by balancing uncertainty, diversity, business risk, edge-case coverage, and production relevance.
- Reliable active learning requires metadata, lineage, versioning, audit logs, reviewer controls, and governance across labeled and unlabeled data assets.
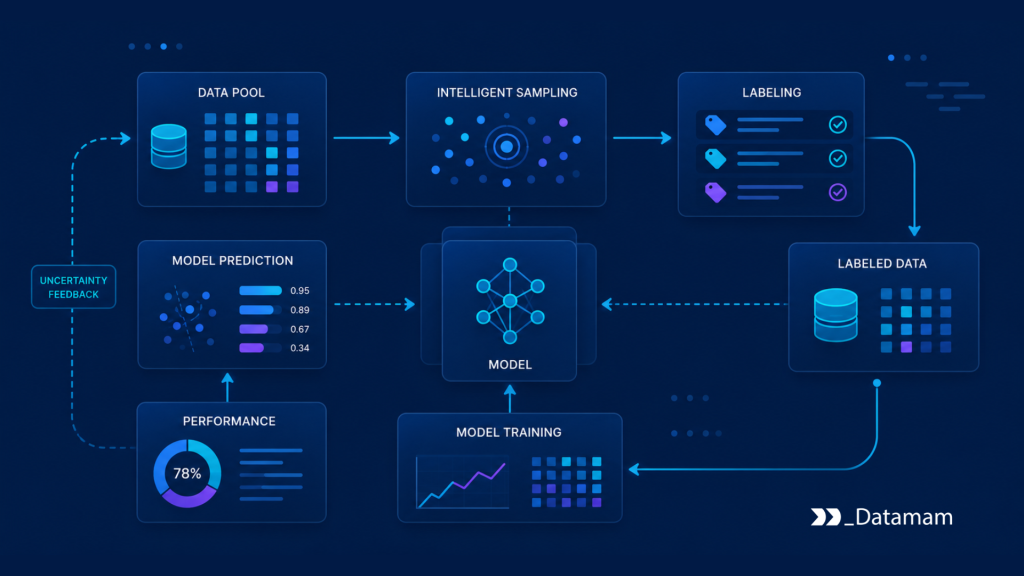
Enterprise AI systems rarely improve just because more data is added. Dataset expansion creates value only when the additional records help the model learn something it does not already understand. Labeling large volumes of redundant, obvious, or low-value records increases cost without necessarily improving model performance.
Active Learning Workflows solve this problem by making dataset expansion selective. Instead of labeling data in bulk, the system identifies records that are likely to improve the model, routes them into review, captures expert labels, and feeds the reviewed examples back into training, validation, or monitoring workflows.
In enterprise environments, active learning is not only a machine learning technique. It is an operational model for managing labeling cost, improving model coverage, reducing blind spots, and maintaining governed feedback loops between production AI behavior and training data improvement.
Why Active Learning Workflows Matter in Enterprise AI Systems
AI systems often operate in environments where unlabeled data is abundant but expert review capacity is limited. Customer conversations, product records, market signals, legal documents, financial disclosures, images, support tickets, and operational logs may produce millions of candidate examples. Labeling all of them is rarely practical.
Active Learning Workflows help teams prioritize. IBM’s explanation of human-in-the-loop AI notes that human feedback can improve models and act as a safeguard when AI systems face ambiguity, bias, or edge cases. Active learning operationalizes that principle by deciding which records should receive human attention first.
Why Dataset Expansion Should Prioritize Informative Records
Informative records are examples that help the model improve. They may be records where the model is uncertain, where predictions conflict across model versions, where the record comes from an underrepresented segment, or where the business impact of an error is high. These records carry more learning value than routine examples the model already handles correctly.
For example, a product matching model may already perform well on exact SKU matches but struggle with bundles, variants, regional titles, or incomplete descriptions. A sentiment model may classify obvious positive and negative feedback correctly but struggle with mixed sentiment, sarcasm, technical complaints, or domain-specific terminology. A market signal classifier may identify common price changes but miss competitor launches or subtle assortment shifts.
Active learning prioritizes those uncertain or high-value examples. This makes dataset expansion more efficient because new labels target the model’s weaknesses rather than increasing dataset size indiscriminately.
How Passive Labeling Creates Cost, Redundancy, and Model Blind Spots
Passive labeling often relies on random sampling, first-in-first-out queues, or bulk annotation of available records. These approaches are easy to run, but they frequently overrepresent common cases. The result is a dataset that grows in volume while providing limited additional model learning.
Redundancy is a major issue. If thousands of similar records are labeled, the model may receive repeated confirmation of patterns it already understands. Meanwhile, rare cases, edge cases, and emerging production failures remain underrepresented. Labeling budgets are consumed without addressing the areas where the model is weakest.
A 2025 paper on active learning methods for efficient data utilization describes active learning as a way to reduce labeling costs while maintaining or improving model quality by selecting the most informative unlabeled instances for annotation. Although implementation varies by domain, the operating logic is consistent: labels should be allocated where they create the greatest learning value.
Operational Problems Created by Inefficient Dataset Expansion
Inefficient dataset expansion usually becomes visible after teams realize that labeling output is increasing faster than model performance. Annotation volume rises, review queues grow, costs expand, but evaluation metrics plateau. In some cases, model performance improves globally while remaining weak in the segments that matter most.
This happens when dataset growth is disconnected from model error analysis, production monitoring, and business risk. Enterprise AI systems need dataset expansion strategies that are guided by learning value, not only data availability.
When Labeling Volume Increases Without Improving Model Performance
Labeling more data can fail to improve performance when the new examples are too similar to existing training records. If the model already handles a category well, adding more examples from that category may produce diminishing returns. The training set grows, but the decision boundary does not improve where the model is uncertain.
This is common in customer support, product classification, market intelligence, compliance review, and document classification workflows. The most available records are often the easiest records. High-volume categories dominate annotation queues, while ambiguous and rare records remain unlabeled.
An active learning pipeline addresses this by using model signals to identify where labels are needed. These signals may include low confidence, high prediction entropy, disagreement between models, unstable predictions over time, or errors discovered in production review. Dataset expansion becomes guided by model improvement rather than annotation throughput.
How Random Sampling Misses Ambiguous, Rare, and High-Value Examples
Random sampling can provide broad coverage, but it is weak when important examples are rare. If a high-impact failure mode represents 1% of the data, a random sample may include too few examples for reliable learning or evaluation. If ambiguous records are uncommon but operationally important, random sampling may underrepresent them.
This matters in enterprise AI because rare examples often carry disproportionate risk. Fraud signals, compliance violations, safety events, competitor launches, product defects, escalated support issues, and unusual market movements may be low-frequency but high-impact. A model that misses them may still show strong aggregate performance.
NIST’s AI Risk Management Framework emphasizes risk management and trustworthy AI practices across the AI lifecycle. For dataset expansion, that means sampling strategies should account for uncertainty, operational impact, and failure severity rather than relying only on broad random selection.
Designing an Active Learning Pipeline for Enterprise AI Workflows
An active learning pipeline connects model scoring, sampling rules, human review, label quality control, dataset versioning, and retraining. It is a feedback loop between model behavior and data improvement. The model identifies examples where it needs help. Human reviewers provide labels. The reviewed examples update the reference dataset. The model is retrained or evaluated against the improved data.
In enterprise systems, this pipeline must be controlled. It should define how records are selected, who reviews them, how labels are approved, how dataset versions are published, and how model improvement is measured.
Connecting Model Uncertainty to Data Selection Decisions
Model uncertainty is one of the most common signals in active learning. When a classifier assigns similar probabilities to multiple labels, the example may be informative. When a matching model cannot confidently decide whether two records refer to the same entity, the pair may be useful for review. Also, when a model output changes across versions, the example may reveal a weak area.
Uncertainty alone is not enough. Some uncertainty reflects genuinely ambiguous data, poor source quality, or cases that do not belong in the model’s scope. Therefore, uncertainty should be combined with metadata such as source type, business segment, risk level, historical error patterns, label availability, and production relevance.
This makes intelligent data sampling more practical. The pipeline does not simply route every uncertain record to reviewers. It selects uncertain records that are likely to improve model behavior and align with operational priorities.
Routing High-Value Records into Human Review and Labeling Queues
Once records are selected, they must be routed into a data labeling workflow. Routing should account for reviewer expertise, record complexity, source sensitivity, language, domain, and business impact. Routine uncertain records may go to standard annotators. High-impact or ambiguous records may require expert review. Sensitive records may require restricted access.
Review queues should include context. Reviewers need source data, model prediction, uncertainty score, candidate labels, annotation guidelines, prior similar examples, and any relevant metadata. Without context, reviewers may produce inconsistent labels, reducing the value of active learning.
Human review should also capture confidence and rationale where useful. A high-confidence expert label can be used differently from a low-confidence label on an inherently ambiguous example.
Feeding Reviewed Examples Back into Training and Evaluation Sets
Reviewed examples should not automatically enter training data without control. Some should be added to training sets. Others should be reserved for validation, test, monitoring, or edge-case evaluation. Some may be excluded because the record is ambiguous, low-quality, duplicated, or outside model scope.
A mature active learning pipeline classifies reviewed records by dataset role. If every difficult example is added to training, evaluation may remain weak. If no difficult examples are reserved for testing, teams cannot measure whether the model improved on the targeted failure mode.
Dataset versioning is essential. Teams should know which active learning batch produced which labels, which dataset version included them, and which model evaluation reflected the update. This turns active learning into a reproducible improvement cycle rather than an informal labeling loop.
Intelligent Data Sampling for Model Improvement
Intelligent data sampling selects records based on learning value and operational relevance. It combines statistical signals with business context. The goal is to choose examples that improve model performance where improvement matters.
This is especially important in enterprise environments where labeling may require domain experts. Expert review time is expensive and limited. Intelligent sampling ensures that experts spend time on examples that are worth their attention.
Selecting Records Based on Uncertainty, Diversity, Risk, and Business Impact
Uncertainty sampling selects examples where the model is least confident. Diversity sampling prevents the selected batch from being too repetitive. Risk-based sampling prioritizes records where errors carry a high business or compliance impact. Business-impact sampling prioritizes segments that matter most for operational workflows.
These methods work best together. A batch selected only by uncertainty may contain many near-duplicate, ambiguous records. A batch selected only by diversity may include records that do not improve model weaknesses. Also, a batch selected only by business value may miss underlying statistical gaps.
For example, a market intelligence AI system may prioritize uncertain competitor launch signals, diverse product categories, high-revenue markets, and recent production errors. This creates a more useful labeling batch than random sampling or uncertainty alone.
Balancing Edge Cases, Common Cases, and Production Distribution
Active learning should not focus only on edge cases. If the dataset becomes dominated by difficult examples, it may drift away from the production distribution. The model may overfit to rare cases and lose performance on common workflows. Therefore, active learning must balance edge-case coverage with representative sampling.
A controlled batch may include a mix of uncertain examples, rare cases, recently observed production records, common examples for calibration, and business-critical segments. The ratio depends on model maturity and use case. Early models may need broad coverage. Mature models may benefit more from targeted edge-case expansion.
The key is sample distribution control. Teams must monitor what active learning adds to the dataset and whether the new examples distort the training or evaluation balance.
Avoiding Feedback Loops and Overfitting in Active Sampling
Active learning can create feedback loops if the model repeatedly selects examples similar to its existing weaknesses. It can also overrepresent records that are uncertain because they are noisy, mislabeled, or outside scope. If these examples enter training without review discipline, the model may learn from noise rather than a useful signal.
To avoid this, active learning workflows should include diversity constraints, exclusion rules, reviewer confidence, duplicate detection, and periodic random baseline sampling. The system should also track whether selected examples actually improve model performance. If a sampling rule produces labels that do not improve results, the rule should be revised.
Governance matters here. Active learning is powerful because it adapts, but that adaptability must be observable and controlled.
Data Labeling Workflow Design for Active Learning
A data labeling workflow for active learning must support more than annotation. It must handle prioritization, reviewer assignment, quality control, dispute resolution, confidence scoring, dataset role assignment, and feedback into model improvement. This workflow determines whether active learning produces reliable ground truth or just faster labeling.
The workflow should be designed for ambiguity because active learning deliberately selects records that the model finds difficult.
Creating Review Rules for Ambiguous and Low-Confidence Predictions
Ambiguous examples need structured review rules. Reviewers should know whether to apply a label, mark the record ambiguous, escalate to expert review, or exclude it from training. Low-confidence model predictions should be presented with enough context for reviewers to understand why the record was selected.
Review rules should also distinguish between useful ambiguity and unusable ambiguity. Some examples are informative because they clarify a boundary between labels. Others are ambiguous because the source record is incomplete or outside the scope. The first category may improve the model. The second may create noise.
Annotation guidelines should include examples, counterexamples, and decision criteria for active learning records. Without strong guidelines, active learning may increase labeling difficulty without improving quality.
Managing Reviewer Assignment, Annotation Quality, and Dispute Resolution
Reviewer assignment should reflect domain expertise. A general annotator may label routine examples, while a domain expert may handle high-risk, technical, legal, medical, financial, or market-specific records. Multilingual data may require language-specific reviewers. Sensitive records may require restricted review permissions.
Annotation quality should be measured through reviewer agreement, expert sampling, gold-standard checks, and disagreement analysis. Disputes should follow a defined adjudication path. If reviewers disagree frequently on a category, the issue may be taxonomy clarity rather than reviewer quality.
This feedback should improve the data labeling workflow. Active learning often exposes the hardest examples in the dataset, so it should also improve labeling rules, taxonomy boundaries, and reviewer calibration.
Preserving Label Confidence, Review History, and Dataset Versioning
Every actively selected record should carry metadata. This includes selection reason, model uncertainty, sampling method, reviewer identity or role, label, confidence score, review status, dispute outcome, guideline version, dataset role, and dataset version.
This metadata allows teams to evaluate whether active learning is working. They can compare labels selected through uncertainty sampling against labels selected through diversity or risk-based sampling. They can inspect whether low-confidence labels should be included in training or reserved for review.
Versioning connects active learning batches to model improvement. If performance improves after a batch is added, teams should know which examples contributed. If performance declines, they should be able to isolate the dataset change.
Measuring Active Learning Workflow Performance
Active learning should be measured as an operational system. It is not enough to count labeled records. Teams need to know whether selected records improved model performance, reduced errors, expanded coverage, improved evaluation stability, and reduced labeling waste.
Measurement should compare active learning against baseline sampling methods. Otherwise, teams cannot know whether the workflow is more efficient than random sampling, stratified sampling, or expert-curated selection.
Tracking Label Efficiency, Model Lift, and Error Reduction Over Time
Label efficiency measures how much model improvement is gained per labeled record. A successful active learning workflow should produce more performance improvement per label than passive labeling. Model lift should be measured across relevant segments, not only aggregate metrics.
Error reduction should be analyzed by failure mode. Did the model improve on ambiguous examples? Rare classes? High-impact business cases? Underrepresented segments? Recent production errors? If active learning improves only global accuracy while critical segments remain weak, the workflow needs adjustment.
Performance should be tracked over time because active learning gains may decline as the model matures. Early rounds may produce large improvements. Later rounds may require more targeted sampling to find remaining weaknesses.
Comparing Active Learning Results Against Baseline Sampling Methods
Baseline comparison is essential. A team should compare active learning batches against random sampling, stratified sampling, or risk-based sampling, depending on the use case. The comparison should evaluate label cost, model improvement, segment coverage, reviewer burden, and error reduction.
Without baselines, active learning may appear effective simply because more labels were added. The real question is whether the selected labels produced more improvement than another sampling method would have produced.
A 2025 human-in-the-loop active learning paper argues that active learning frameworks are valuable because they can improve labeling efficiency by directing expert effort toward useful queries rather than treating all unlabeled records equally. For enterprise teams, the same concept must be validated through measurable workflow performance, not assumed. Efficient Human-in-the-Loop Active Learning provides a research-oriented example of this direction.
Monitoring Distribution Shift as New Examples Enter the Dataset
Active learning changes dataset composition. If the workflow selects mostly uncertain and difficult examples, the labeled dataset may become less representative of production distribution. This is useful for targeted improvement but risky if uncontrolled.
Distribution monitoring should track class balance, source mix, market coverage, language distribution, confidence scores, edge-case volume, and production alignment. Teams should know whether active learning is improving coverage or distorting the dataset.
Monitoring also helps detect when the production environment changes. If new types of uncertainty appear, active learning can route those examples into review. This creates an adaptive feedback loop between production behavior and training data expansion.
Technology Stack Behind Active Learning Workflows
Enterprise active learning requires infrastructure across scoring, sampling, labeling, storage, orchestration, observability, lineage, and governance. The stack must connect unlabeled data pools, model predictions, sampling logic, human review, ground truth datasets, and retraining workflows.
The goal is to make dataset expansion controlled and repeatable. Teams should be able to explain why records were selected, how they were labeled, where they entered the dataset, and how they affected model performance.
Orchestration, Model Scoring, and Sampling Pipelines
Airflow can coordinate active learning workflows by scheduling model scoring, uncertainty calculation, sample selection, labeling queue creation, review completion checks, dataset publication, and retraining triggers. Kafka can support event-driven ingestion of production errors, user feedback, or newly observed records. Spark can process large unlabeled pools for scoring, filtering, deduplication, diversity selection, and distribution analysis.
The model scoring layer assigns predictions and confidence scores. The sampling layer applies selection rules. The orchestration layer ensures the workflow runs in the correct order and handles failures, retries, and review dependencies.
This architecture prevents active learning from becoming an ad hoc notebook process. It turns it into an operational pipeline.
Storage, Metadata, and Versioning Across Labeled and Unlabeled Data
Unlabeled records, selected samples, reviewed labels, rejected records, and dataset versions should be stored with durable metadata. Snowflake, BigQuery, and Databricks can support raw pools, selected batches, labeling states, review outcomes, and published training datasets.
Metadata should include selection strategy, uncertainty score, diversity cluster, source, timestamp, reviewer confidence, label version, dataset role, and model version. This makes it possible to compare active learning rounds and evaluate which sampling methods produce the most useful labels.
Versioning should apply to sampling rules, selected batches, labels, and final dataset releases. Without versioning, teams cannot reproduce model evaluations or determine which dataset expansion decisions affected performance.
Observability, Lineage, Audit Logs, and Governance Controls
Observability tools such as Prometheus can monitor scoring jobs, sampling pipelines, labeling throughput, review backlog, model lift, distribution changes, and workflow failures. Validation frameworks can test whether selected batches meet coverage, diversity, and quality thresholds before publication.
Lineage systems should connect unlabeled records to selected samples, reviewed labels, dataset versions, training runs, evaluation outputs, and production models. Audit logs should preserve selection rules, reviewer decisions, overrides, approvals, and publication events.
Gartner’s 2025 Data and Analytics Governance Primer states that data and analytics success relies on governance capabilities, processes, practices, and enabling technologies. Active learning workflows need that same governance discipline because dataset expansion directly changes model behavior.
Governance and Compliance in Active Learning Pipelines
Active learning governance defines who can approve sampling rules, who can access selected records, who can label sensitive examples, how labels are reviewed, and how dataset versions are published. This is especially important because active learning often selects difficult, ambiguous, high-impact, or sensitive records.
Governance does not prevent active learning from being efficient. It ensures that efficiency does not come at the cost of traceability, fairness, or control.
Managing Access Controls, Reviewer Permissions, and Source Accountability
Access controls determine who can view, label, or approve selected records. Some examples may contain sensitive customer data, regulated content, proprietary documents, or commercially sensitive market information. Active learning systems should not route these records into general labeling queues without permission controls.
Reviewer permissions should reflect expertise. Domain experts may handle high-impact records. Compliance reviewers may handle restricted examples. Standard annotators may handle routine ambiguous records. The workflow should preserve who reviewed each record and under which guideline version.
Source accountability also matters. Selected records should preserve source origin, collection context, usage restrictions, and quality status. A record that is useful for model debugging may not be suitable for training if its source context is weak or restricted.
Supporting Audit Readiness for Label Selection and Dataset Expansion Decisions
Audit readiness requires evidence of how the dataset expanded. Teams should be able to show which records were selected, why they were selected, who labeled them, which labels were approved, which records were excluded, and which model versions used the resulting dataset.
This is particularly important when AI systems influence customer experience, pricing, compliance, risk assessment, market intelligence, or operational automation. If a model output is challenged, teams need to understand whether the underlying dataset expansion process was controlled.
OECD’s 2025 Digital Government Index and Open, Useful and Re-usable Data Index emphasize coherent data foundations and reusable data practices in digital environments. Active learning workflows follow the same operating principle: dataset expansion becomes more reliable when selection, labeling, reuse, and governance are documented.
You can run an external data infrastructure audit with our team to review your current setup and understand what is required to build a reliable, enterprise-scale external data infrastructure.
Active Learning Workflows as AI Infrastructure
Active Learning Workflows become AI infrastructure when they operate continuously across model development, monitoring, and retraining. They connect production errors, model uncertainty, human review, dataset expansion, and performance measurement into a controlled improvement cycle.
At scale, this matters because AI systems face changing data. New customer behaviors appear. Market conditions shift. Products evolve. Policies change. Source formats change. Active learning helps AI teams respond by selecting the examples that reveal where the model needs improvement.
Strengthening Training Data Quality, Model Monitoring, and Retraining Decisions
Training data quality improves when new labels address known weaknesses. Model monitoring becomes more useful when uncertain or failed production examples flow into review. Retraining decisions become more evidence-based when teams can see which new examples were added and whether they improved performance.
For example, a model that fails on a new product category can route uncertain examples from that category into expert review. A customer support model that struggles with a new issue type can prioritize recent examples for labeling. A market intelligence model that misses subtle competitor actions can select ambiguous signals for review.
This creates a closed loop. Production behavior informs sampling. Sampling informs labeling. Labeling informs retraining. Retraining informs the next round of monitoring.
Building Long-Term Trust in Dataset Expansion Processes
Long-term trust depends on knowing that dataset expansion is intentional, measured, and governed. Business teams need confidence that the model is improving on relevant cases. AI teams need evidence that labels are useful. Governance teams need traceability. Procurement evaluators need to know that data operations are controlled.
Active learning provides a disciplined approach when it is implemented with metadata, lineage, versioning, quality checks, and audit logs. It helps organizations avoid uncontrolled data growth and focus instead on targeted model improvement.
Ultimately, the value of active learning is not only reduced labeling cost. It is the ability to expand datasets in a way that improves model reliability where reliability matters most.
Conclusion: Turning Dataset Expansion into a Controlled Model Improvement System
Enterprise AI systems need more than large labeled datasets. They need dataset expansion workflows that identify which records are worth labeling, route them to the right reviewers, preserve label quality, and measure whether new labels improve model performance.
Active Learning Workflows provide that operating model. By combining an active learning pipeline, data labeling workflow, intelligent data sampling, human review, versioning, lineage, and governance, enterprises can expand datasets more efficiently while reducing blind spots and labeling waste.
The capability matters because labeling capacity is limited, and model weaknesses are not distributed evenly. Passive labeling may increase volume without improving reliability. Active learning turns dataset expansion into a controlled improvement system.
A structured review can help evaluate whether current AI data workflows have reliable active learning controls, sampling logic, labeling queues, reviewer governance, versioned datasets, and audit-ready model improvement records. You can run an external data infrastructure audit with our team to review your current setup and understand what is required to build a reliable, enterprise-scale external data infrastructure.


