Key Takeaways
- How Autonomous Vehicle Training Data supports perception model reliability across roads, weather, lighting, and traffic conditions
- Why autonomous driving datasets must include diverse vehicle sensor data from cameras, lidar, radar, maps, and localization systems
- How lidar annotation, image labeling, and sensor fusion labeling improve object detection, segmentation, and tracking quality
- Why perception training data requires validation, versioning, lineage, scenario coverage, and governance controls
- How structured training data pipelines reduce annotation rework, improve model evaluation, and support safer perception system development
Autonomous vehicle perception systems depend on their ability to interpret the road environment accurately, consistently, and fast enough to support safe driving decisions. Cameras, lidar, radar, ultrasonic sensors, GPS, IMU signals, and HD maps generate enormous amounts of vehicle sensor data, but raw sensor streams do not become reliable AI inputs automatically. Autonomous Vehicle Training Data must be collected, labeled, validated, versioned, and governed so perception models can detect lanes, vehicles, pedestrians, cyclists, signs, traffic lights, construction zones, road edges, and rare edge cases across real operating conditions.
The Training Data Gap in Autonomous Vehicle Perception
Autonomous vehicle perception systems must operate in open, changing, and safety-critical environments. They need to recognize common driving patterns while also handling low-frequency but high-risk scenarios: occluded pedestrians, unusual road geometry, emergency vehicles, fallen objects, temporary lane closures, construction workers, low-light conditions, glare, rain, snow, dust, and unusual vehicle behavior. NHTSA’s automated vehicle safety resources emphasize that automated driving technologies are evaluated in the context of safety, public roads, and real operating environments.
The training data challenge is that many of the most important perception scenarios are not evenly distributed. Everyday highway following data is easier to collect than rare near-miss, adverse-weather, unusual-object, or vulnerable-road-user cases. Therefore, Autonomous Vehicle Training Data must be intentionally designed around coverage, not just volume.
Why Perception Models Depend on Autonomous Vehicle Training Data
Perception models learn what road objects look like, where they appear, how they move, and how they relate to the vehicle’s driving environment. If the training data overrepresents clear daytime roads and underrepresents rain, night, dense urban intersections, construction zones, or unusual vehicle types, the model may perform unevenly. This creates a practical limitation: a model can appear strong in aggregate metrics while still failing in high-risk edge cases.
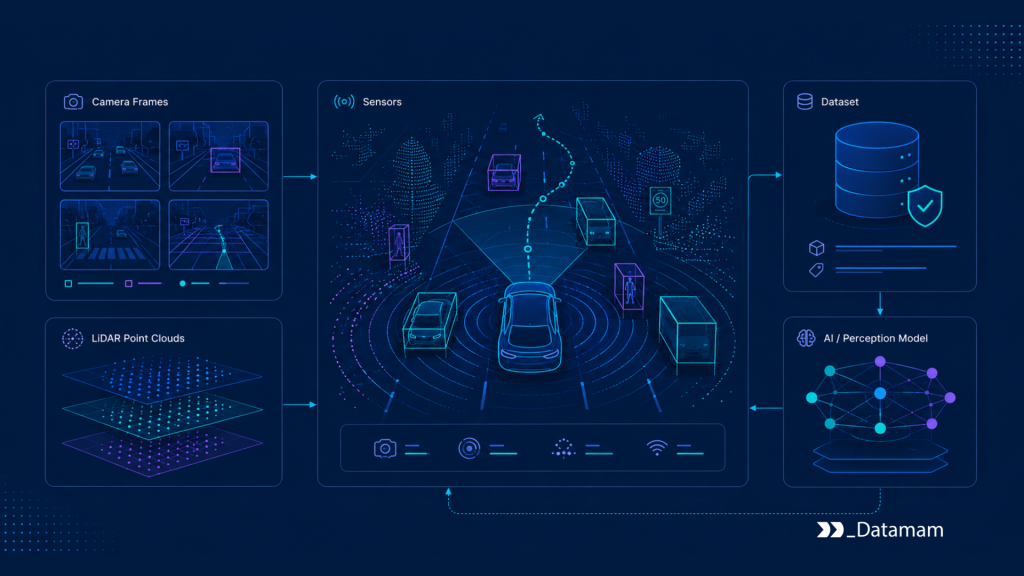
Autonomous Vehicle Training Data must therefore include diverse camera images, lidar point clouds, radar returns, object tracks, lane geometry, map context, and temporal sequences. The dataset should teach the model not only object appearance, but also depth, motion, occlusion, uncertainty, and spatial relationships.
Where Raw Vehicle Sensor Data Falls Short for AI Development
Raw vehicle sensor data is not automatically usable for model training. Camera feeds may contain motion blur, glare, lens obstruction, exposure differences, or weather effects. Lidar point clouds may be sparse, noisy, reflective, or affected by sensor placement. Radar may detect velocity well but provide less semantic detail. GPS and localization signals may drift. HD maps may be outdated or incomplete.
As a result, raw vehicle sensor data must be synchronized, cleaned, labeled, validated, and converted into structured perception training data. Without this preparation layer, model teams may train on inconsistent frames, misaligned sensors, weak labels, or scenarios that do not reflect the intended operational design domain.
Autonomous Vehicle Training Data as a Perception Foundation
Autonomous Vehicle Training Data becomes commercially and operationally valuable when it is treated as a governed AI asset rather than a storage archive of driving logs. Perception systems require datasets that connect sensor streams, object labels, timestamps, calibration metadata, scenario tags, road context, and model evaluation outcomes. ISO/PAS 8800:2024 is relevant because it focuses on safety and artificial intelligence in road vehicles, reinforcing the need for disciplined data, validation, and lifecycle controls in automotive AI systems.
For perception development, this means datasets must be designed around repeatability. Engineers need to know what data trained a model, which labels were used, which edge cases were included, and whether new data improved or degraded performance.
Building Representative Autonomous Driving Datasets Across Conditions
Autonomous driving datasets must represent the environments where the system is expected to operate. A perception model for highway autonomy needs different coverage from a robotaxi model operating in dense urban neighborhoods. A system designed for sunny suburban environments cannot be assumed to perform equally well in rain, fog, snow, tunnels, construction areas, or complex pedestrian environments.
Representative datasets should include road type, weather, lighting, traffic density, region, road surface, signage, lane structure, vehicle classes, vulnerable road users, and unusual objects. Dataset design should be measured by scenario coverage and operational relevance, not just total miles collected.
Structuring Perception Training Data for Model Reliability
Perception training data must preserve relationships between objects, sensors, time, and map context. A pedestrian label is more useful when it includes position, bounding box, motion state, occlusion level, distance, sensor visibility, and relationship to crosswalk or lane geometry. Similarly, a vehicle object should connect to frame sequence, heading, velocity, classification, tracking ID, and confidence level.
Reliable datasets often include synchronized camera frames, lidar sweeps, radar tracks, calibration files, ego-vehicle pose, HD map context, object labels, scenario tags, and validation status. This structure allows model teams to train and evaluate perception systems with consistent assumptions rather than loosely connected sensor files.
Using Lidar Annotation to Improve Spatial Understanding
Lidar annotation helps perception models understand three-dimensional structure. While cameras provide semantic richness, lidar point clouds provide depth, geometry, distance, and spatial boundaries. Lidar annotation commonly involves 3D bounding boxes, object classification, tracking IDs, segmentation masks, lane boundaries, drivable space, and static obstacle labeling.
High-quality lidar annotation requires clear instructions for object boundaries, partial occlusion, point sparsity, moving objects, and ambiguous classes. For example, labeling a pedestrian partly hidden behind a parked vehicle requires a consistent rule for visible geometry and expected object extent. These decisions directly affect object detection, tracking, and sensor fusion performance.
External Data Requirements for Vehicle Sensor Data
Perception systems often require a combination of internally collected fleet data, controlled test-track data, simulation outputs, public datasets, mapping data, synthetic data, and third-party sensor datasets. The value comes from combining these sources into a coherent training corpus that covers normal driving, rare events, and operational edge cases. The challenge is not simply gathering more autonomous driving datasets. It is making them consistent, traceable, and useful for model development.
Each source must be evaluated by sensor configuration, geography, weather coverage, licensing rights, label quality, scenario relevance, and compatibility with the intended operational design domain.
Sourcing Data Across Cameras, Lidar, Radar, and HD Maps
Vehicle sensor data may include multi-camera video, lidar point clouds, radar tracks, ultrasonic signals, GPS, IMU, CAN bus data, and HD map layers. Each sensor contributes different perception strengths. Cameras support classification and scene semantics. Lidar supports depth and geometry. Radar supports velocity and resilience in some visibility conditions. HD maps provide lane, intersection, and traffic control context.
Sourcing must document sensor placement, calibration, timestamp synchronization, geographic environment, and collection conditions. Without source-level documentation, model teams may struggle to explain performance gaps between datasets or determine whether a dataset is suitable for a specific autonomy function.
Normalizing Sensor Metadata, Coordinates, and Scenario Tags
Autonomous driving data is difficult to compare unless metadata is normalized. Different vehicles may use different sensor layouts, frame rates, coordinate systems, calibration formats, map schemas, and annotation categories. Normalization aligns timestamps, coordinate frames, object classes, sensor identifiers, route metadata, and scenario tags into a consistent framework.
For example, a lidar point cloud must be aligned with camera frames, vehicle pose, and object labels. If timestamps or calibration files are inconsistent, the same object may appear shifted across sensors. For perception training data, small alignment errors can become significant model errors.
Managing Scenario Diversity Across Operational Design Domains
Autonomous vehicle systems are usually designed for specific operational design domains. These may include certain road types, speeds, weather conditions, geographies, traffic rules, or service areas. Dataset coverage must be evaluated against those boundaries. A model intended for urban robotaxi use needs strong coverage of crosswalks, cyclists, pedestrians, double-parked vehicles, emergency vehicles, and complex intersections.
By contrast, a highway trucking perception system may require stronger coverage of long-range detection, lane merges, debris, work zones, ramps, and heavy-vehicle interactions. Scenario diversity should be tracked explicitly so teams can identify coverage gaps before deployment.
Infrastructure Requirements for Autonomous Vehicle Training Data Pipelines
Autonomous vehicle training data pipelines must handle high-volume sensor logs, large binary files, spatial-temporal indexing, annotation workflows, validation controls, model feedback loops, and reproducible training sets. The infrastructure must support both engineering scale and safety discipline. For autonomous vehicle teams, this reinforces a core principle: perception data pipelines cannot be informal. They need engineering controls, quality gates, and governance evidence.
Continuous Data Intake for Sensor Logs, Labels, and Scenario Metadata
Training data pipelines must ingest sensor logs from vehicles, test fleets, simulation systems, labeling platforms, and validation environments. Intake workflows may include secure transfer, object storage, metadata extraction, calibration validation, de-identification, where applicable, and routing to annotation or review queues. Apache Airflow can orchestrate these workflows by managing dependencies, retries, data quality checks, and scheduled processing.
At scale, continuous intake helps teams convert driving data into curated training sets. This is especially important when teams use model failures, disengagements, or hard-negative mining to select new training examples.
Validation Controls for Sensor Alignment and Label Quality
Validation controls prevent unreliable perception training data from entering model workflows. Sensor-level checks may evaluate timestamp synchronization, calibration validity, missing frames, corrupted files, camera exposure, lidar density, radar availability, and pose consistency. Label-level checks may evaluate class completeness, bounding box geometry, tracking continuity, occlusion handling, and annotation agreement.
For lidar annotation, validation should include 3D box fit, orientation consistency, object dimensions, temporal continuity, and cross-sensor alignment. These controls reduce the risk that model performance is limited by annotation noise rather than perception architecture.
Versioning, Lineage, and Reproducibility for Perception Models
Perception model development requires a clear lineage across raw sensor logs, selected scenarios, labels, transformations, dataset splits, and model training runs. If a model improves, teams need to know whether the improvement came from architecture changes, added edge cases, better annotation, or altered preprocessing. If performance degrades, teams need to trace the cause quickly.
Versioning should track sensor source, collection date, calibration version, annotation batch, reviewer workflow, transformation code, scenario taxonomy, and train-validation-test split. Without lineage, autonomous driving datasets become difficult to reproduce, audit, or use as safety evidence.
Technology Stack Behind Autonomous Vehicle Training Data Systems
A mature autonomous vehicle training data system operates across data collection, processing, annotation, storage, governance, and model integration. It must support video, point clouds, radar data, maps, telemetry, labels, scenario metadata, and model outputs. The stack needs to handle petabyte-scale storage while also preserving fine-grained traceability for safety review, dataset debugging, and model evaluation.
The most effective systems connect data engineering, perception engineering, annotation operations, safety validation, and MLOps into one controlled workflow rather than allowing each team to manage separate datasets.
Collection and Orchestration Using Airflow, Kafka, and Controlled Intake Pipelines
Collection workflows may use secure fleet upload, cloud object storage, sensor log ingestion, event-triggered capture, simulation export, and controlled third-party dataset intake. Apache Airflow can orchestrate ingestion, calibration checks, scenario extraction, sampling workflows, and routing into labeling or storage systems. Kafka can support streaming ingestion where vehicle events, model outputs, or monitoring signals need rapid processing.
These tools help teams move from ad hoc sensor file handling to a repeatable data intake model. That repeatability matters because perception development depends on continuous data improvement.
Processing and Transformation Through Spark, dbt, and Sensor ETL Workflows
Processing layers transform raw sensor data into structured training datasets. Spark can process large metadata tables, sensor indexes, scenario catalogs, object tracks, and annotation outputs at scale. Sensor ETL workflows can synchronize timestamps, align coordinate frames, extract key frames, generate point cloud projections, join labels with map context, and classify scenarios.
dbt can manage standardized analytical models for dataset metadata, QA reporting, scenario coverage, and annotation metrics. This allows perception teams to understand dataset composition and quality before running expensive model training cycles.
Storage, Analytics, and Governance in Databricks, Snowflake, BigQuery, or Lakehouse Environments
Autonomous vehicle datasets often require object storage for raw video, lidar, radar, and sensor logs, combined with analytical storage for metadata, labels, scenarios, and audit records. Databricks, Snowflake, BigQuery, or lakehouse environments can support dataset profiling, scenario search, training set construction, and model evaluation analytics.
Governance controls should include role-based access, audit logs, data lineage, retention rules, source documentation, annotation status, and dataset approval workflows. These controls are essential because perception training data influences safety-critical model behavior.
Commercial Impact of High-Quality Autonomous Vehicle Training Data
The commercial value of Autonomous Vehicle Training Data appears when better datasets improve perception reliability, reduce annotation waste, accelerate validation cycles, and support safer deployment decisions. Strong data does not guarantee autonomy success, but weak data almost always increases rework, model instability, and safety risk. For autonomous vehicle developers, suppliers, and mobility operators, perception data quality directly affects engineering velocity, operational readiness, and confidence in deployment boundaries.
High-quality training data also improves collaboration between perception teams, safety teams, product leaders, and regulatory stakeholders because the evidence behind model behavior becomes easier to inspect.
Improving Perception Generalization Across Driving Conditions
Perception generalization is critical because autonomous vehicles must operate across changing road environments. A detector that works in clear daylight may fail in glare, rain, tunnels, dense traffic, or construction areas. A pedestrian model may perform differently across clothing types, occlusion levels, lighting conditions, and distance ranges.
Representative autonomous driving datasets help models learn patterns that remain stable across driving conditions. Commercial impact often appears as fewer scenario-specific retraining cycles, stronger rollout readiness, and reduced manual intervention in post-test analysis.
Reducing Annotation Rework and Dataset Preparation Time
Annotation is expensive, especially when it involves lidar annotation, multi-camera alignment, 3D bounding boxes, semantic segmentation, and tracking across time. Poor annotation guidelines create inconsistent labels and repeated review cycles. Clear taxonomies, reviewer calibration, automated QA checks, and adjudication workflows reduce rework.
At scale, this can shift expert time away from correcting basic labeling defects and toward high-value edge cases. The result is faster dataset preparation, better perception training data, and improved use of annotation budgets.
Supporting Faster Validation and Scenario-Based Evaluation
Validation cycles improve when datasets are organized by scenario, geography, weather, lighting, object type, and operational design domain. Teams can test perception models against known hard cases rather than relying only on aggregate metrics. This supports more targeted model evaluation and clearer evidence generation.
Scenario-based datasets also allow safety and engineering teams to track whether specific weaknesses are improving over time. If vulnerable-road-user detection is weak in low light, the team can build, label, validate, and monitor that scenario category directly.
Risk Exposure When Perception Training Data Is Incomplete
Incomplete perception training data creates safety, engineering, commercial, and governance risk. A model may miss an unusual obstacle, misclassify a vulnerable road user, lose track of a cyclist, misread temporary lane markings, or fail to detect construction workers. These issues often reflect data limitations as much as model limitations.
When perception systems influence vehicle behavior, dataset quality becomes part of safety risk management. The organization must understand not only how the model performs, but what the model has and has not learned from the training data.
Bias and Performance Drift Across Roads, Weather, and Sensor Configurations
Dataset bias can occur when training data overrepresents certain cities, road types, weather conditions, sensor configurations, or traffic patterns. A system trained mainly in well-marked urban areas may underperform on rural roads, faded lane markings, informal intersections, or regions with different driving behavior. Sensor upgrades can also create distribution shifts if new camera, lidar, or radar outputs differ from the original training data.
Teams should monitor performance by geography, road type, weather, lighting, sensor version, and object class. Without this monitoring, perception failures may remain hidden inside strong average metrics.
Reliability Gaps From Weak Lidar Annotation and Object Taxonomies
Weak annotation standards create reliability gaps. If one annotator labels a partially occluded pedestrian and another does not, model targets become inconsistent. If vehicle classes are too broad, the model may fail to distinguish buses, trucks, trailers, motorcycles, scooters, or emergency vehicles. Also, if 3D bounding boxes vary in orientation or extent, lidar-based detection becomes unstable.
Strong object taxonomies and lidar annotation protocols are essential. They define what the model is expected to learn and how ambiguous cases should be handled across large annotation teams.
Compliance, Auditability, and Safety Evidence Gaps
Autonomous vehicle development increasingly requires evidence that systems are tested, monitored, and improved under controlled processes. If training data provenance is unclear, teams may struggle to show how a model was trained, which scenarios were included, or whether known weaknesses were addressed. This creates internal and external confidence issues.
Auditability depends on lineage, dataset versioning, annotation records, validation outputs, and model evaluation history. Without these controls, even strong perception performance may be difficult to explain or defend.
Governance Requirements for Autonomous Driving Datasets
Governance must be embedded throughout the dataset lifecycle. Vehicle sensor data may include public-road imagery, pedestrians, license plates, location traces, infrastructure details, and operational logs. It may also involve proprietary test routes, supplier data, and region-specific privacy obligations. Data governance defines who can access the data, how long it is retained, how labels are verified, and how datasets are approved for model training.
For autonomous vehicle teams, governance is not only about compliance. It is about maintaining confidence that perception systems are trained on appropriate, traceable, and validated data.
Privacy Controls, Access Management, and Audit Logs
Vehicle sensor data can contain sensitive information, especially in public road environments. Camera footage may capture faces, plates, homes, businesses, and bystanders. Location data may reveal route patterns or operational domains. Governance controls should include de-identification where appropriate, access restrictions, encryption, retention policies, and audit logs.
Audit logs should record data access, export, transformation, annotation, and deletion events. These records help teams manage privacy exposure and demonstrate that autonomous driving datasets are handled under controlled procedures.
Data Lineage Across Training, Validation, and Testing Sets
Data lineage allows teams to understand how each sensor sequence moved from raw capture to model training. Traceability should cover vehicle, sensor configuration, collection date, route, weather, scenario tags, annotation version, preprocessing logic, validation outcome, and dataset split. This matters because leakage between training and validation sets can inflate performance metrics.
Lineage also supports debugging. If a model fails in a scenario, teams can determine whether the issue originated from missing data, weak labels, sensor misalignment, scenario imbalance, or model architecture.
Cross-Border Data Considerations in Vehicle Sensor Data
Autonomous vehicle developers may collect and process data across multiple countries, each with different rules around personal data, mapping, public-road imagery, and data transfer. A dataset usable in one jurisdiction may require additional controls in another. Cross-border governance should document source rights, data processing location, access roles, transfer basis, and permitted model development activities.
This is especially important for global autonomy platforms. Perception systems need regional diversity, but dataset expansion must be managed responsibly.
Evaluating Autonomous Vehicle Training Data Readiness
Autonomous Vehicle Training Data becomes valuable when it supports repeatable model improvement, not merely when it exists in storage. Readiness depends on scenario coverage, sensor diversity, annotation quality, metadata completeness, validation controls, governance, and integration with ML workflows. Perception teams should evaluate whether datasets represent the operational design domain, whether labels match the perception task, and whether lineage supports reproducibility.
A readiness review helps identify data gaps before they become model failures, validation delays, or deployment constraints.
How Perception Teams Assess Dataset Coverage and Quality
A structured assessment should evaluate road type coverage, weather distribution, lighting conditions, object class balance, vulnerable-road-user representation, sensor configuration, geographic diversity, rare event coverage, and scenario metadata. It should also measure annotation consistency, lidar box quality, tracking continuity, missing frames, calibration validity, and label completeness.
For perception training data, quality must be evaluated by scenario and task. A dataset may contain millions of frames while still lacking enough examples of construction zones, emergency vehicles, unusual obstacles, or low-light pedestrians.
When Organizations Need a Perception Dataset Architecture Review
A dataset architecture review becomes useful when teams rely on fragmented sensor logs, inconsistent annotation workflows, unclear dataset versions, or disconnected model evaluation systems. The review should assess intake processes, sensor synchronization, lidar annotation quality, validation controls, storage architecture, lineage tracking, governance posture, and integration with training workflows.
The output should clarify where dataset risk accumulates, where vehicle sensor data is underutilized, and which infrastructure improvements would make autonomous driving datasets more reliable for perception system development.
Conclusion: Autonomous Vehicle Training Data as Perception Infrastructure
Autonomous vehicle perception systems depend on data infrastructure as much as model architecture. Autonomous Vehicle Training Data must be representative, labeled, normalized, validated, versioned, and governed before it can reliably support safety-critical perception. Lidar annotation provides spatial precision. Camera and radar data provide semantic and motion context. Perception training data provides the scenario coverage needed for model improvement. Vehicle sensor data provides scale, but infrastructure determines whether that scale becomes usable intelligence.
Ultimately, organizations that treat autonomous driving datasets as governed perception infrastructure will be better positioned to build systems that are more reliable, reproducible, and ready for controlled deployment.


