Key Takeaways
- How Biometric Training Data supports identity verification AI across face matching, document comparison, and liveness detection workflows
- Why facial recognition datasets must reflect demographic, device, lighting, pose, and image quality variation
- How liveness detection data helps systems identify spoofing attempts, presentation attacks, and synthetic identity risks
- Why biometric datasets require strict governance, consent controls, auditability, data lineage, and privacy safeguards
- How structured biometric data pipelines improve model reliability, reduce manual review, and support safer identity verification deployment
Identity verification systems depend on biometric AI models that can compare, classify, and validate human identity signals under real-world conditions. Face images, video selfies, document photos, device metadata, motion cues, and liveness checks generate high-value identity signals, but they do not become reliable AI inputs automatically. Biometric Training Data must be collected, labeled, validated, versioned, and governed so identity verification AI can operate across demographics, lighting conditions, device types, fraud attempts, image quality levels, and regulatory environments.
The Training Data Gap in Identity Verification Systems
Identity verification systems are expected to operate in uncontrolled environments. A customer may submit a selfie from a low-quality phone camera, a dim room, a moving vehicle, or a crowded public space. The identity document image may be cropped, blurred, glared, expired, damaged, or captured at an angle. A fraud attempt may involve a printed photo, replayed video, deepfake, mask, synthetic face, or manipulated document. Therefore, biometric AI systems need training data that reflects real verification conditions.
Why Identity Verification AI Depends on Biometric Training Data
Identity verification AI learns from examples of real and fraudulent identity attempts. If training data overrepresents high-quality images and underrepresents low light, blur, pose variation, darker skin tones, older faces, mobile capture artifacts, or cross-device differences, the system may perform unevenly in production. A model can appear accurate in aggregate while producing higher false rejection or false acceptance rates for specific user groups or capture conditions.
Biometric Training Data must therefore include both genuine and attack examples. It should teach models how legitimate identity signals vary naturally and how fraudulent signals appear under different methods. The commercial value of identity verification AI depends on reducing friction for legitimate users while detecting high-risk attempts reliably.
Where Raw Biometric Data Falls Short for AI Development
Raw biometric data is rarely model-ready. Face images may contain glare, occlusion, compression artifacts, motion blur, poor framing, uneven lighting, or inconsistent resolution. Video selfies may include dropped frames, device-specific color profiles, or unstable motion. Identity document images may contain different layouts, holograms, fonts, security features, and capture quality issues.
Raw data also lacks the labels needed for AI development. Teams must know whether the sample represents a genuine user, an impostor, a presentation attack, a failed capture, a synthetic face, or a document mismatch. Without structured labeling and validation, facial recognition datasets may teach the model unreliable patterns.
Biometric Training Data as an Identity Verification Foundation
Biometric Training Data becomes commercially useful when it is treated as a governed identity infrastructure rather than a folder of face images or video clips. Identity verification workflows require datasets that connect biometric samples, document records, device context, liveness outcomes, fraud labels, demographic attributes, where legally permitted, capture metadata, and model evaluation results. The purpose is not simply to train a more accurate model. It is to build a verification system that is reliable, measurable, explainable, and safe to operate.
ISO/IEC JTC 1/SC 37 develops biometric standards covering data interchange, performance testing, interfaces, profiles, and societal considerations. This makes it a strong institutional reference for organizations building biometric systems that need interoperability and disciplined evaluation.
Building Representative Facial Recognition Datasets Across User Groups
Representative facial recognition datasets must reflect the identity populations and capture environments the system will serve. This includes variation across age, gender, skin tone, facial hair, eyewear, head coverings, pose, expression, camera type, lighting, geography, and image quality. In enterprise identity verification, dataset representation is not only a model performance issue. It is also a customer experience and risk issue.
If certain groups experience higher false rejection, onboarding friction increases. If certain conditions produce higher false acceptance, fraud exposure increases. Therefore, dataset design should evaluate model performance by subgroup and capture condition, not only by overall accuracy.
Structuring Biometric Training Data for Model Reliability
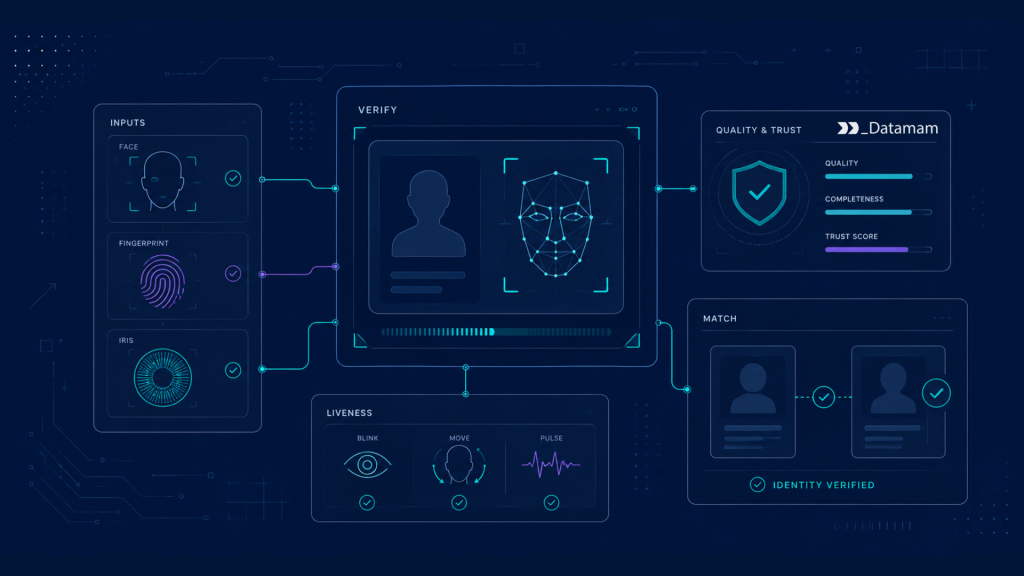
Reliable biometric datasets preserve relationships between identity record, capture event, biometric sample, document image, device metadata, liveness outcome, fraud signal, and verification result. A face image becomes more useful when connected to capture quality scores, pose metadata, illumination conditions, device class, match decision, manual review outcome, and attack label.
This structure supports model training, threshold calibration, quality assessment, and post-deployment monitoring. Without structured relationships, identity verification teams may know whether a model passed a benchmark but not why it fails in specific capture conditions, markets, or customer groups.
Using Liveness Detection Data to Improve Fraud Resistance
Liveness detection data helps identity verification systems distinguish a live user from a spoofing attempt. Depending on the workflow, liveness data may include active gestures, passive video signals, depth cues, texture patterns, lighting changes, device motion, blink behavior, or challenge-response interactions. The dataset must include both genuine live captures and presentation attacks.
Attack examples may include printed photos, screen replays, masks, synthetic videos, injected media, deepfake outputs, and document-photo substitutions. High-quality liveness detection data should label attack type, capture method, device context, quality level, and detection outcome. These labels help models improve fraud resistance without increasing unnecessary friction for legitimate users.
External Data Requirements for Identity Verification AI
Identity verification AI often requires more than one internal customer dataset. Teams may need consented user captures, fraud attempt repositories, device-specific data, document image samples, public benchmarks, synthetic augmentation, and region-specific capture examples. The challenge is combining these inputs into governed training sets without weakening privacy, legality, or model reliability.
External data should be evaluated on a consent basis, licensing terms, demographic coverage, capture conditions, device diversity, label quality, permitted use, and cross-border restrictions. For biometric systems, weak sourcing discipline creates risk even when model performance appears strong.
Sourcing Data Across Face Images, Video Selfies, Documents, and Device Signals
Biometric AI systems often require multiple data types. Face images support matching. Video selfies support liveness analysis. Identity document images support document-to-selfie comparison. Device metadata may help identify capture environment and fraud patterns. Manual review outcomes help label difficult cases. Fraud operations data helps identify new attack methods.
Each source must be documented carefully. Teams should know where the data came from, how it was collected, whether consent was obtained, whether it can be used for model training, and whether restrictions apply. Without this documentation, valuable biometric datasets may become difficult to scale, audit, or deploy commercially.
Normalizing Capture Metadata, Identity Labels, and Quality Scores
Biometric data is inconsistent across devices, markets, and vendors. One capture system may store image quality scores; another may store only raw images. One vendor may label spoofing attempts by attack type, while another records only pass or fail. Document capture workflows may vary by country, document type, and camera quality.
Normalization aligns capture metadata, identity labels, device categories, image quality scores, liveness outcomes, fraud categories, timestamps, and review results. This allows identity verification AI teams to compare model behavior across workflows. Without normalization, a dataset may combine incompatible labels and produce unreliable performance analysis.
Managing Data Diversity Across Devices, Demographics, and Fraud Scenarios
Data diversity must be measured across the conditions that affect identity verification outcomes. Device class, camera resolution, image compression, lighting, pose, face occlusion, age group, geography, and document type can all influence verification performance. Fraud diversity also matters because attackers adapt quickly.
Facial recognition datasets should include legitimate variation, while liveness detection data should include realistic attack variation. If fraud examples are too simple, models may perform well in testing but fail against newer spoofing methods. If genuine examples are too narrow, legitimate customers may experience excessive friction.
Infrastructure Requirements for Biometric Training Data Pipelines
Biometric data pipelines must manage sensitive personal data, large image and video files, metadata, annotation workflows, privacy controls, model evaluation outputs, and reproducible training sets. The pipeline must also support governance because biometric data is among the most sensitive categories of identity information. The EU Artificial Intelligence Act places strong obligations around high-risk AI systems and includes specific treatment of biometric systems, reinforcing the need for risk management, data governance, transparency, and human oversight.
For identity verification AI, this means data infrastructure must support both model development and institutional accountability. Dataset quality, sourcing, labeling, access, and performance measurement all need to be traceable.
Continuous Data Intake for Captures, Labels, and Fraud Signals
Biometric training pipelines must ingest face images, video clips, document captures, liveness outcomes, manual review labels, fraud investigation records, and device metadata through controlled workflows. Intake may involve secure transfer from verification platforms, annotation systems, fraud operations tools, cloud storage, and identity databases. Apache Airflow can orchestrate recurring ingestion, validation, redaction, routing, and dataset publication.
Continuous intake helps teams respond to changing fraud patterns and capture conditions. As new devices, document types, or attack methods appear, the training corpus must evolve without becoming uncontrolled.
Validation Controls for Image Quality, Labels, and Liveness Outcomes
Validation controls prevent unreliable samples from entering model workflows. Image checks may evaluate blur, glare, resolution, face position, occlusion, exposure, compression, and framing. Video checks may evaluate frame rate, duration, motion, dropped frames, and signal consistency. Label checks may evaluate match status, fraud category, liveness outcome, manual review agreement, and missing metadata.
For liveness detection data, validation should confirm that attack labels are accurate and specific. A replay attack, printed photo, mask, deepfake, and injection attack should not be collapsed into one vague category if the model is expected to detect different threat patterns.
Versioning, Lineage, and Reproducibility for Biometric Models
Identity verification AI teams need to know exactly which dataset version trained a model. This requires lineage across raw captures, quality filters, de-identification or minimization steps, annotation batches, fraud labels, transformations, thresholds, and train-validation-test splits. If performance changes, teams need to understand whether the cause was data, labeling, preprocessing, threshold calibration, or model architecture.
Versioning should track source system, capture date, device type, label protocol, reviewer status, liveness category, transformation code, validation result, and dataset split. Without lineage, biometric models become difficult to audit and difficult to improve systematically.
Technology Stack Behind Biometric Training Data Systems
A mature biometric training data system operates across secure intake, preprocessing, annotation, transformation, storage, governance, and model integration. It must support images, videos, metadata, labels, fraud categories, quality scores, review outcomes, and model outputs. The stack must also support strict access management because biometric identifiers cannot be treated like ordinary behavioral data.
The strongest systems connect data engineering, identity operations, fraud risk, compliance, MLOps, and product teams into one controlled workflow. Without that connection, biometric datasets become fragmented across vendors, review teams, fraud tools, and model development environments.
Collection and Orchestration Using Airflow, Kafka, and Controlled Intake Pipelines
Collection workflows may use secure transfer from identity verification platforms, document capture systems, fraud tools, cloud storage, and manual review environments. Apache Airflow can orchestrate ingestion, quality checks, label routing, transformation, dataset approval, and publication to model training environments. Kafka can support streaming ingestion where fraud alerts, verification outcomes, or capture quality signals need rapid processing.
These tools help teams move from ad hoc image exports to repeatable biometric data intake. Repeatability matters because identity verification systems must continuously adapt to new capture behavior, device patterns, and fraud methods.
Processing and Transformation Through Spark, dbt, and Biometric ETL Workflows
Processing layers transform raw biometric data into structured training datasets. Spark can process large volumes of image metadata, video metadata, quality scores, fraud labels, and model evaluation records at scale. Biometric ETL workflows can standardize file formats, remove unusable samples, align labels, extract quality metrics, link documents to selfies, and create dataset manifests.
dbt can manage standardized analytical models for dataset profiling, quality reporting, fairness evaluation, annotation metrics, and review outcomes. This allows identity verification teams to understand dataset composition before training or deploying models.
Storage, Analytics, and Governance in Databricks, Snowflake, BigQuery, or Lakehouse Environments
Biometric AI datasets often require object storage for images and videos, plus analytical storage for metadata, labels, quality scores, fraud categories, and audit records. Databricks, Snowflake, BigQuery, or lakehouse environments can support dataset profiling, cohort selection, model evaluation, and governance reporting.
Governance controls should include role-based access, encryption, audit logs, retention rules, source documentation, consent status, minimization controls, and data lineage. These controls matter because biometric data is sensitive, persistent, and directly tied to identity verification outcomes.
Commercial Impact of High-Quality Biometric Training Data
The commercial value of Biometric Training Data appears when better datasets improve verification accuracy, reduce customer friction, strengthen fraud detection, and support auditability. Strong data does not guarantee perfect identity verification, but weak data almost always increases false rejections, manual review workload, fraud exposure, and governance risk. For financial services, marketplaces, telecom, travel, gaming, healthcare, and digital identity providers, biometric data quality directly affects conversion, security, and trust.
High-quality datasets also improve collaboration between product, fraud, compliance, and machine learning teams because model behavior can be tied back to known capture conditions and risk categories.
Improving Verification Accuracy Across Real-World Conditions
Verification accuracy improves when training data reflects real capture conditions. Customers rarely submit perfect images. They use different devices, lighting environments, camera angles, backgrounds, and document types. Models trained only on clean samples may struggle with real onboarding workflows.
Representative Biometric Training Data helps models perform more consistently across capture quality levels and user groups. Commercial impact often appears as fewer false rejections, fewer unnecessary retries, better conversion, and more efficient manual review routing.
Reducing Manual Review and Customer Onboarding Friction
Manual review is expensive and slows user onboarding. Weak biometric models send too many legitimate users into review or force repeated capture attempts. Better facial recognition datasets and liveness detection data reduce avoidable friction by improving confidence in automated decisions.
The goal is not to eliminate all human review. High-risk or ambiguous cases still require escalation. The business value is in reserving human review for genuinely uncertain cases while allowing low-risk legitimate users to complete verification with less interruption.
Strengthening Fraud Detection and Presentation Attack Resistance
Fraud resistance improves when datasets include realistic and evolving attack examples. Liveness detection data should include printed photos, replayed videos, masks, synthetic media, manipulated images, injection attacks, and document-selfie mismatch patterns where relevant. Models trained on narrow fraud examples may perform well against simple attacks but fail against more sophisticated methods.
Structured biometric pipelines allow fraud teams to feed confirmed attack patterns back into training and validation workflows. This creates a learning loop between fraud operations and identity verification AI development.
Risk Exposure When Biometric Training Data Is Incomplete
Incomplete biometric datasets create operational, commercial, compliance, and trust risk. A verification system may reject legitimate users, accept fraudulent attempts, perform unevenly across demographic groups, or fail to detect new spoofing methods. These failures often originate from dataset limitations rather than model architecture alone.
When identity verification AI determines access to financial services, employment platforms, marketplaces, healthcare portals, travel systems, or regulated accounts, data quality becomes a control function. Teams must understand what the model has learned and where its limits remain.
Bias and Performance Drift Across User Groups and Capture Conditions
Bias can occur when training data underrepresents certain demographics, devices, regions, or image conditions. A system may perform better for users captured on newer phones or in well-lit environments and worse for users with older devices or difficult lighting. Performance drift can also occur as fraud methods evolve, device cameras change, or onboarding flows are redesigned.
Teams should monitor performance by demographic attributes where legally permitted, device type, geography, image quality, document type, and capture channel. Without monitoring, uneven performance may remain hidden inside strong average metrics.
Reliability Gaps from Weak Liveness Labels and Fraud Taxonomies
Weak labeling creates reliability gaps. If all spoofing attempts are labeled as “fraud” without attack type, the model may fail to learn meaningful distinctions. If synthetic media, replay attacks, printed photos, masks, and injection attacks are not separated, liveness models may underperform against emerging threats.
Strong fraud taxonomies are essential. Liveness detection data should include attack type, capture method, device context, confidence level, manual review result, and outcome. These labels help identity verification AI adapt as fraud patterns evolve.
Privacy, Consent, and Auditability Risks in Biometric Data
Biometric data is sensitive because it is persistent and tied to identity. If data provenance, consent basis, retention policy, access logs, or permitted use are unclear, organizations may face regulatory, legal, and reputational risk. This becomes more serious when biometric datasets are used across vendors, regions, or model development teams.
Auditability depends on source documentation, access logs, consent records, dataset approvals, deletion workflows, and lineage. Without these controls, even high-performing biometric systems may become difficult to justify to compliance teams, regulators, customers, or enterprise buyers.
Governance Requirements for Identity Verification AI Datasets
Governance must be embedded throughout the biometric dataset lifecycle. Identity data may combine face images, video selfies, document images, device signals, fraud notes, manual review outcomes, and customer account metadata. Each data type carries different sensitivity and permitted-use constraints. NIST’s AI Risk Management Framework provides a practical reference for mapping, measuring, managing, and governing AI risks across system lifecycles.
For biometric AI, these principles translate into source controls, access restrictions, minimization, bias testing, audit logs, human oversight, validation evidence, and traceability from biometric sample to model behavior.
Consent, Minimization, and Secure Biometric Handling
Biometric datasets should include clear documentation of consent basis, permitted use, retention period, deletion obligations, and data minimization rules. Teams should avoid retaining unnecessary biometric samples or metadata when derived features or lower-risk representations are sufficient for a given workflow. Access controls should restrict who can view face images, videos, document images, fraud labels, and identity metadata.
Secure handling should apply across ingestion, annotation, storage, training, evaluation, and deletion. Every movement of sensitive biometric data should be logged and governed.
Data Lineage Across Training, Validation, and Testing Sets
Data lineage allows teams to understand how each biometric sample moved from capture to model training. Traceability should cover source system, capture event, consent status, quality filters, label version, liveness category, reviewer decision, transformation logic, validation outcome, and dataset split. This matters because leakage between training and testing data can inflate performance metrics.
Lineage also supports debugging. If a model fails for a specific capture condition or user group, teams can review whether the dataset included enough comparable samples and whether labels were consistent.
Cross-Border Data Considerations in Biometric AI Development
Biometric data rules vary significantly across jurisdictions. Some regions apply strict consent requirements, special-category data rules, localization expectations, or transfer restrictions. A dataset that can be used for identity verification in one jurisdiction may require additional review before being used for model training in another.
Cross-border controls should document source rights, transfer basis, storage location, access roles, permitted use, and deletion requirements. This reduces the risk that biometric training data becomes technically useful but legally constrained.
Evaluating Biometric Training Data Readiness
Biometric Training Data becomes valuable when it supports repeatable model improvement, not simply when captures exist in storage. Readiness depends on representation, image quality, fraud coverage, label consistency, consent status, governance, and integration with model workflows. Identity verification teams should evaluate whether datasets represent real onboarding conditions, whether liveness labels are specific enough, and whether lineage supports auditability.
A readiness review helps identify dataset gaps before they become failed verifications, fraud losses, customer friction, or compliance concerns.
How Identity Verification Teams Assess Dataset Coverage and Quality
A structured assessment should evaluate demographic representation where lawful, device diversity, image quality distribution, lighting conditions, pose variation, document types, geography, fraud categories, liveness examples, and manual review outcomes. It should also measure label consistency, reviewer agreement, missing metadata, duplicate rates, quality score distribution, and dataset split integrity.
For identity verification AI, quality must be evaluated by workflow and risk. A dataset may contain millions of face images while still lacking enough realistic attack examples or difficult legitimate captures.
When Organizations Need a Biometric Dataset Architecture Review
A dataset architecture review becomes useful when teams rely on fragmented capture exports, inconsistent fraud labels, unclear consent records, manual annotation spreadsheets, or disconnected model evaluation systems. The review should assess intake workflows, image quality controls, liveness labeling, validation rules, storage architecture, lineage tracking, governance posture, and model integration readiness.
The output should clarify where dataset risk accumulates, where facial recognition datasets may limit model performance, and which infrastructure improvements would make identity verification AI more reliable and auditable.
Conclusion: Biometric Training Data as Identity Verification Infrastructure
Identity verification systems depend on biometric data infrastructure as much as model sophistication. Biometric Training Data must be representative, labeled, normalized, validated, versioned, and governed before it can reliably support verification decisions. Facial recognition datasets provide the matching foundation. Liveness detection data provides fraud resistance. Identity verification AI converts these signals into onboarding, account access, fraud prevention, and risk controls.
Ultimately, organizations that treat biometric datasets as governed identity infrastructure will be better positioned to deploy verification systems that are accurate, auditable, privacy-conscious, and commercially scalable.


