Key Takeaways
- Governance must begin before data enters training, evaluation, or inference workflows.
- Training data controls reduce model risk by improving traceability, validation, and source accountability.
- Late-stage model review cannot compensate for weak data lineage or poor documentation.
- Enterprise AI governance is becoming a lifecycle discipline across data, legal, compliance, security, and AI teams.
AI systems rarely become risky only at the point of deployment. Risk enters much earlier, when data is sourced, filtered, labeled, transformed, stored, and approved for model use. By the time a model reaches final review, many of the most important governance decisions have already been made, either intentionally through controls or informally through undocumented data handling.
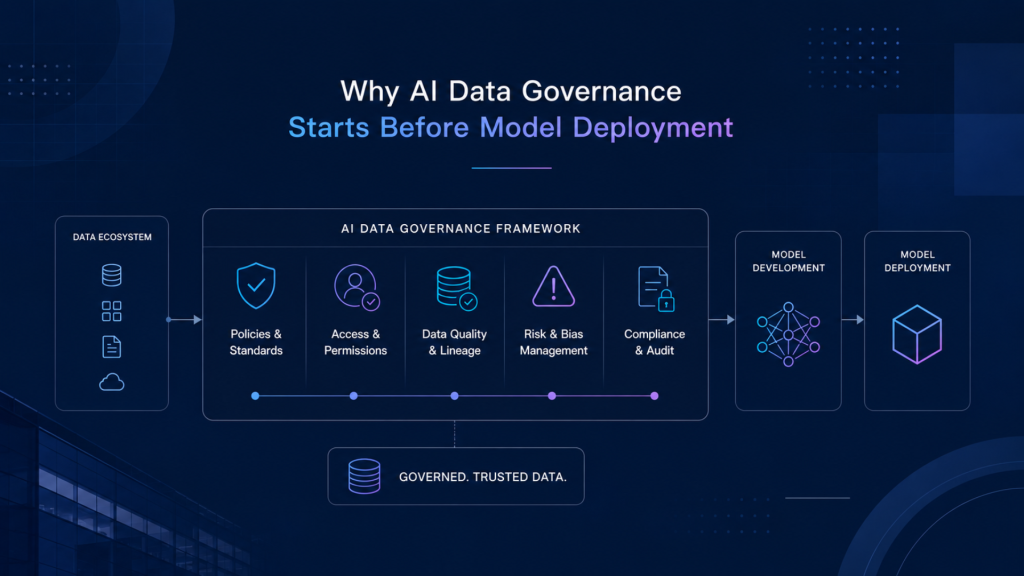
AI Data Governance therefore, has to begin before model deployment. Enterprise teams need to understand where training data came from, how it was prepared, what restrictions apply, whether labels are reliable, how data quality was validated, and whether the dataset can be audited later. Without these controls, model review becomes a late-stage attempt to correct risks that are already embedded in the system.
Governance Begins at the Data Foundation, Not the Model Review Stage
Enterprise AI governance is often associated with model approval, risk classification, explainability review, and deployment controls. Those steps matter, but they occur too late if the data foundation is already weak. The model inherits assumptions from the data used to train, validate, and evaluate it. If those assumptions are undocumented or poorly controlled, governance teams are forced to investigate risk after it has already entered the model lifecycle.
NIST’s AI Risk Management Framework emphasizes governance, measurement, mapping, and management across the AI lifecycle. For enterprise teams, the implication is direct: governance cannot be concentrated only at the deployment stage. It has to operate across the data lifecycle where many AI risks originate.
Enterprise Teams Need Controls Before Data Enters Training Pipelines
Controls are most effective before data enters training pipelines. At that point, teams can still evaluate source quality, usage rights, privacy constraints, sensitive fields, duplication, bias risk, and representativeness. Once data is embedded into model training, remediation becomes more difficult because the model may already reflect patterns that came from weak inputs.
Early controls should clarify which data sources are approved, what restrictions apply, how sensitive data is handled, how labels are created, and which quality checks must be passed before a dataset is used. These decisions create a governance boundary around the training process.
In practice, training data controls reduce uncertainty. They give AI teams a structured path for development while giving legal, compliance, and security teams visibility before risk becomes harder to unwind.
Model Risk Management Depends on Knowing How Inputs Were Sourced and Prepared
Model risk management depends on evidence. Teams need to know how inputs were sourced, what transformations were applied, whether fields were excluded, how labels were assigned, and whether dataset versions were preserved. Without that evidence, model risk review becomes speculative.
A model may behave unexpectedly because of weak labels, missing segments, outdated examples, poor source quality, or distribution shift. If data preparation was not documented, teams may struggle to identify the root cause. This delays remediation and weakens trust in the AI system.
Accordingly, model risk management has to begin with data risk management. The model cannot be fully understood if the input environment remains opaque.
The Hidden Risk of Treating Governance as a Deployment Checkpoint
Treating governance as a deployment checkpoint creates a false sense of control. A final review can confirm whether documentation exists, whether performance metrics meet thresholds, and whether business owners approve deployment. However, it cannot easily reconstruct source decisions, labeling choices, consent conditions, data transformations, or quality failures that occurred earlier.
Gartner’s Predicts 2025: The Data and Analytics Governance Reset Continues With AI notes that generative AI and the growing need to govern unstructured data are straining traditional data governance operating models. This is especially relevant for AI teams because many model inputs now include documents, conversations, images, web content, product data, support records, and other less structured sources that require earlier governance discipline.
Late-Stage Review Cannot Fix Weak Source Documentation or Poor Dataset Lineage
Late-stage governance review can identify missing documentation, but it cannot always repair it. If source documentation was not captured at the time of collection, teams may have to reconstruct ownership, permissions, collection methods, transformation logic, and retention constraints later. That process is slow and often incomplete.
Poor dataset lineage creates a similar problem. If teams cannot trace how data moved from source to training set, they cannot confidently explain which inputs influenced the model. This weakens auditability and makes performance investigations harder.
A deployment review may pause the model, but the underlying issue remains data-level opacity. Earlier governance prevents this by preserving documentation and lineage while data is still moving through the pipeline.
Training Data Controls Reduce Rework, Compliance Friction, and Approval Delays
Earlier controls improve speed because they reduce late-stage uncertainty. When data sources are approved, schemas validated, sensitive fields managed, labels documented, and dataset versions preserved, deployment review becomes more efficient. Legal and compliance teams can evaluate evidence instead of requesting reconstruction.
Weak controls create the opposite effect. AI teams may retrain models, rebuild datasets, remove questionable sources, relabel examples, or repeat evaluation because governance issues appear late. These delays are expensive, especially when product, engineering, or business teams have already planned around deployment timelines.
Therefore, early AI Data Governance is not only a risk function. It is a delivery accelerator when implemented with discipline.
Why Enterprise AI Programs Need Earlier Accountability
AI governance requires accountability across the teams that influence data before the model exists. Data engineering teams manage pipelines. AI teams define training and evaluation requirements. Domain experts validate labels. Legal teams review permissible use. Compliance teams assess obligations. Security teams manage access and controls. Business owners define acceptable risk and intended use.
McKinsey’s State of AI 2025 reports that AI use is widespread, but many organizations still struggle to move from adoption to scaled enterprise impact. Governance accountability is one reason. AI cannot scale reliably when responsibility is unclear across the data and model lifecycle. To address these challenges, companies are increasingly turning to ai training data solutions for enterprises that streamline the data management process and clarify roles throughout the lifecycle. By leveraging advanced technologies and clear governance frameworks, organizations can enhance accountability and improve the quality of their AI models. This shift not only fosters greater collaboration among teams but also facilitates compliance and mitigates risks associated with data usage.
Legal, Compliance, Data, and AI Teams Need Shared Rules Before Development Accelerates
AI development often accelerates faster than governance alignment. Teams gather data, build prototypes, test models, and prepare deployment while legal and compliance requirements are still being clarified. This creates friction because review teams enter late and may challenge assumptions that were already built into the system.
Shared rules reduce this risk. They define acceptable data sources, restricted data categories, required documentation, labeling standards, retention policies, access controls, and escalation conditions. When teams understand these rules before development accelerates, AI workflows become more predictable.
Enterprise AI governance works best when it gives teams clear operating boundaries, not when it functions only as a final approval gate.
Governance Gaps Become More Expensive Once Models Enter Business Workflows
Governance gaps become more expensive after AI enters business workflows. At that stage, the model may influence customer decisions, employee workflows, pricing logic, risk scoring, recommendations, or automated prioritization. Remediation may require retraining, rollback, customer communication, compliance review, or business process redesign.
Earlier accountability reduces these costs by identifying data risks before they become operational risks. If a source is not appropriate, it can be excluded before training. When labels are inconsistent, they can be corrected before evaluation. If sensitive fields are present, they can be removed or controlled before deployment.
In practice, early governance shifts AI risk management from reactive correction to controlled development.
The Control Layer Behind Responsible AI Systems
Responsible AI systems require a control layer that operates across data preparation, model development, evaluation, deployment, and monitoring. Policies are necessary, but they are insufficient without technical systems that make controls enforceable and visible. Governance has to be embedded into workflows so that teams can see whether data is valid, current, traceable, and approved for use.
The World Economic Forum’s 2025 analysis on scaling AI with strategy, data, and workforce readiness argues that leaders need strong data foundations to scale AI across the enterprise. Governance is a central part of that foundation because production AI depends on data systems that can be trusted and managed over time.
Validation, Versioning, and Metadata Make Training Inputs Easier to Audit
Validation helps teams confirm that datasets meet expected quality standards. Versioning preserves the exact state of data used for training, validation, and evaluation. Metadata records source, ownership, collection timing, label method, transformation logic, access rules, and usage restrictions.
Tools such as Great Expectations can support schema validation, completeness checks, anomaly detection, and field-level quality rules. Data lineage tools and metadata systems help teams understand how datasets changed before they influenced model behavior. Snowflake, BigQuery, and Databricks can support large-scale dataset storage, versioning, and analysis.
When these controls exist, audit questions become easier to answer. Which data trained the model? Which labels were used? What changed between versions? Were restricted fields removed? Which sources were approved? Governance becomes evidence-based rather than memory-based.
Observability and Lineage Help Teams Detect Drift, Quality Issues, and Policy Violations
Observability makes governance continuous. Production AI systems rely on data that changes over time, so teams need visibility into freshness, schema changes, missing values, distribution shifts, source failures, and pipeline latency. Without observability, governance teams may discover problems only after model behavior changes.
Prometheus and other observability systems can monitor pipeline health and alert teams to failures or degradation. Lineage systems connect data changes to downstream models, dashboards, and AI workflows. Metadata systems help teams determine whether a policy violation affected a specific dataset or model version.
This matters for both performance and compliance. A source failure may create model drift. A schema change may break evaluation logic. An unauthorized field may enter a training dataset. Continuous controls allow teams to detect and respond before the issue becomes a production failure.
How Earlier Governance Strengthens Model Risk Management
Model risk management improves when governance begins at the data layer. Many model risks are not purely algorithmic. They come from source quality, data coverage, label inconsistency, outdated examples, missing metadata, unclear permissions, or weak monitoring. Earlier governance helps teams identify these risks before they become harder to isolate.
The World Bank’s Digital Progress and Trends Report 2025 emphasizes that AI development depends on foundations that support inclusive, sustainable, and responsible adoption. For enterprises, the same principle applies at the organizational level. Strong AI foundations require data controls, governance systems, and risk management practices that begin before deployment.
Clear Data Standards Improve Trust in Evaluation, Monitoring, and Retraining Decisions
Data standards define what acceptable inputs look like. They establish expectations for completeness, freshness, label quality, source documentation, coverage, and governance approval. These standards improve trust in evaluation because teams know whether the test data reflects real conditions. Monitoring also becomes more meaningful because teams can detect when production inputs deviate from approved baselines.
Retraining decisions depend on the same discipline. If performance declines, teams need to know whether the issue comes from model drift, input drift, source degradation, or business change. Clear standards make this diagnosis faster.
In practice, data standards turn model risk management into a more controlled process. Teams can evaluate changes against known criteria rather than relying on informal judgment.
Source-Level Oversight Helps Leaders Separate Model Failure from Data Failure
AI systems can fail for many reasons. A model may be poorly designed. Evaluation may be incomplete. Data may be outdated. A source may change structure. Labels may drift. Edge cases may be missing. Without source-level oversight, leaders may not know where the failure originated.
Source-level oversight helps separate model failure from data failure. It tracks source quality, collection methods, transformation steps, usage restrictions, and change history. When a model behaves unexpectedly, teams can investigate whether the input environment changed before assuming the model itself is defective.
This distinction matters for executive decision-making. If the issue is data failure, retraining the same model without fixing inputs may reproduce the problem. Governance helps teams identify the right intervention.
Why AI Data Governance Is Becoming an Executive Requirement
AI governance is becoming an executive requirement because AI systems increasingly influence decisions that affect revenue, compliance, customers, employees, and risk exposure. As AI moves into production, leaders need assurance that the data foundation is controlled before deployment decisions are made. Governance cannot be delegated entirely to technical teams because the consequences extend across the enterprise.
IBM’s 2025 CDO Study emphasizes the importance of high-quality data and strong governance frameworks for unlocking value from proprietary and ecosystem data. For AI leaders, the implication is straightforward: enterprise AI governance depends on the maturity of the data systems behind AI initiatives.
Production AI Requires Governed Data Systems Before Deployment Decisions Are Made
Deployment decisions should be based on more than model performance. Leaders need evidence that training and evaluation data are appropriate, governed, documented, and representative. They also need confidence that inference data will remain reliable after launch.
Governed data systems provide this evidence. They preserve source documentation, validation results, lineage, metadata, access controls, audit logs, and version history. They also support compliance review by making data usage more transparent.
Without these systems, deployment approval becomes harder to defend. A model may appear effective, but the organization may not be able to explain the data conditions that made it effective or the controls that will keep it reliable.
Scalable Enterprise AI Governance Depends on Controls Embedded Across the Data Lifecycle
Scalable enterprise AI governance requires controls across the data lifecycle. Data must be qualified before use, validated before training, versioned during development, monitored after deployment, and governed throughout its use. This requires coordination across legal, compliance, data, AI, security, and business teams.
Ultimately, AI Data Governance starts before model deployment because model risk begins before deployment. Training data controls reduce uncertainty, improve auditability, and strengthen model risk management. Enterprise AI governance becomes effective when controls are embedded into sourcing, preparation, validation, monitoring, and lifecycle management.
Organizations that govern data early will be better positioned to scale AI systems with trust. Those that wait until deployment review may continue to approve pilots, but they will struggle to build production AI systems that are traceable, compliant, and resilient under enterprise scrutiny.


