
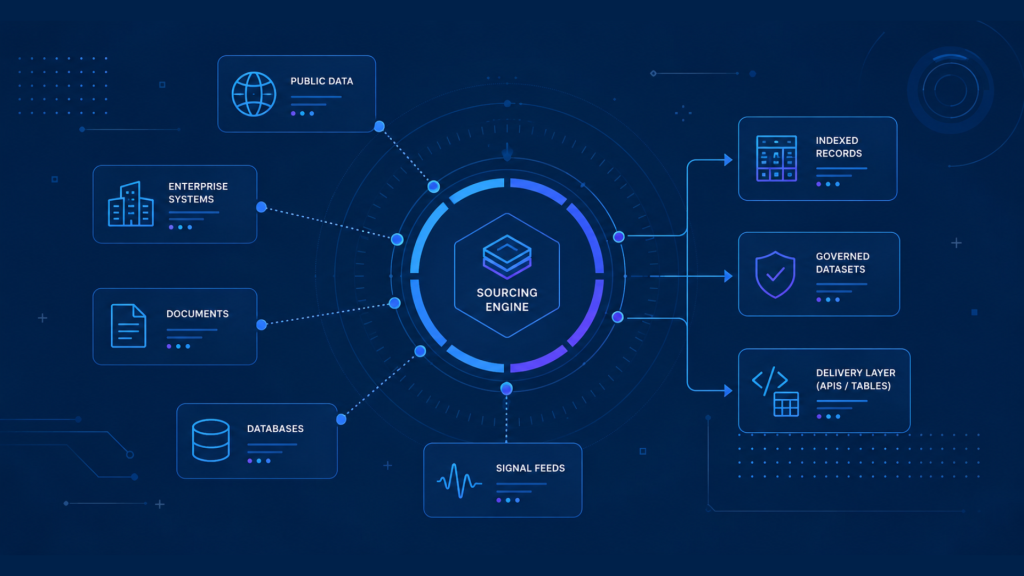
Data Sourcing Services have become the upstream foundation of external data infrastructure. Enterprise teams can no longer treat source discovery as informal research, vendor search, or isolated data acquisition planning. Every downstream capability, from analytics and pricing intelligence to AI development and risk monitoring, depends on identifying, qualifying, governing, and preparing the right sources for scalable use. The structural issue is not access to more data. It is the ability to build a reliable source layer before collection, integration, analysis, or automation begins.
Data Sourcing Services as the Foundation of External Data Infrastructure
External data programs often fail before collection starts. The failure point is usually not the crawler, API, warehouse, dashboard, or model. It is source selection. If the enterprise relies on incomplete, unstable, low-quality, or poorly governed sources, downstream systems inherit weak coverage and inconsistent signal quality. Therefore, data sourcing must be treated as a strategic infrastructure function. It defines where external signals originate, how they are evaluated, which sources warrant operational investment, and how source decisions are documented for long-term use.
From Opportunistic Source Discovery to Governed Data Supply
Many organizations begin external data initiatives by searching for obvious sources, purchasing vendor feeds, or asking internal analysts to find useful websites. That approach can work for early exploration, but it breaks when external data becomes part of recurring business operations. Governed data supply requires a disciplined process for identifying source categories, evaluating coverage, assessing stability, documenting access feasibility, and mapping source value to business use cases. In practice, external data sourcing must move from opportunistic discovery to a repeatable operating model.
Why Source Quality Determines Downstream Data Reliability
Source quality determines whether the rest of the data pipeline can be trusted. A technically successful extraction process does not create reliable intelligence if the source is incomplete, stale, biased, unstable, or irrelevant to the decision being supported. Moreover, source quality affects validation rules, normalization logic, refresh cadence, and monitoring requirements. Business data sourcing, therefore, begins with a simple but critical principle: reliable data infrastructure is impossible without reliable source foundations.
The Enterprise External Data Sourcing Gap
The enterprise external data sourcing gap appears when organizations invest heavily in analytics, AI, dashboards, and cloud systems while underinvesting in the source layer that feeds them. Internal systems show what the company already knows. External sources reveal what is happening outside the company’s boundaries. However, external source landscapes are fragmented, volatile, and uneven in quality. As a result, enterprises need a structured capability for identifying and governing sources before turning them into production data assets.
Why Internal Systems Cannot Identify the Full Market Signal Landscape
Internal systems are designed to capture internal transactions, operations, customer relationships, financial performance, and workflow activity. They are not designed to identify emerging competitor movement, public procurement opportunities, marketplace changes, regulatory updates, pricing shifts, consumer sentiment, or new public data sources. Consequently, internal BI environments can become structurally blind to external signals. Data sourcing solutions close this gap by mapping the source landscape outside the enterprise and connecting it to strategic, operational, and analytical use cases.
How Fragmented Source Discovery Creates Strategic Blind Spots
Fragmented source discovery creates blind spots because different teams search for different inputs without a shared framework. Strategy teams may track competitors. Risk teams may monitor public filings. AI teams may search for training data. Pricing teams may watch marketplaces. Procurement teams may evaluate vendor feeds. However, without an enterprise sourcing model, coverage gaps remain invisible. The organization may believe it has external visibility while relying on a narrow, inconsistent, or duplicated set of sources.
Why Data Sourcing Services Have Become Infrastructure
Data sourcing becomes infrastructure when external sources support repeatable enterprise decisions. Once source inputs feed pricing systems, AI pipelines, competitive monitoring, risk dashboards, market expansion models, or compliance workflows, source selection is no longer a research activity. It becomes a control point in the enterprise data supply chain. Gartner’s 2025 data and analytics predictions state that by 2027, 50% of business decisions will be augmented or automated by AI agents, which increases the need for governed data, analytics, and decision flows.
External Data Dependency Across Strategy, AI, Risk, and Pricing
External data dependency is now visible across multiple enterprise functions. Strategy leaders need market and competitor signals. AI teams need representative external datasets. Risk teams need public indicators, regulatory updates, and third-party signals. Pricing teams need marketplace, competitor, and assortment data. Compliance teams need traceable sourcing and documented governance. Therefore, enterprise data sourcing must operate across business functions, not as a single departmental research task. It must create a reusable source foundation for multiple downstream systems.
Public Data Sourcing Across Complex and Changing Digital Environments
Public data sourcing sounds simple until it operates at enterprise scale. Also, public sources differ widely in structure, quality, accessibility, update frequency, legal context, and operational stability. A regulatory portal may be highly authoritative but difficult to normalize. A marketplace may provide high-frequency pricing signals but shift structure frequently. Public records may be valuable but fragmented by jurisdiction. In this context, public data sourcing requires source mapping, feasibility analysis, governance review, and operational design before acquisition begins.
Governance Requirements for Enterprise Data Sourcing
Governance begins at source selection, not after data has already entered the pipeline. Enterprises must understand where data originates, whether it is permitted for the intended use, how access is managed, what documentation exists, and how source changes will be monitored. OECD’s 2025 work on trustworthy AI emphasizes governance, data, digital infrastructure, skills, procurement, and partnerships as key enablers, with transparency, risk management, and oversight as guardrails.
| Enterprise Driver | What Changed | Why Data Sourcing Infrastructure Is Required |
| External data dependency | Strategy, AI, pricing, risk, and compliance teams rely on external signals | Source selection must be governed before collection begins |
| Fragmented source landscapes | Useful signals are distributed across websites, portals, vendors, APIs, public records, and marketplaces | Enterprises need systematic source mapping and coverage analysis |
| AI-ready data requirements | Models require representative, traceable, and high-quality inputs | Source quality directly affects model reliability and downstream data preparation |
| Compliance expectations | Source use must be documented, reviewed, and aligned with governance standards | Informal sourcing creates weak auditability and unclear risk ownership |
| Scalable data operations | External pipelines expand across markets, languages, categories, and jurisdictions | Source stability, refresh planning, and feasibility must be evaluated early |
The Operating Model Behind Data Sourcing Services
At enterprise scale, Data Sourcing Services are not the same as finding a list of websites or buying a dataset. They represent an operating model for building the source layer of external data infrastructure. This model identifies relevant sources, qualifies them for enterprise use, evaluates technical access, applies governance review, prioritizes by business value, and prepares handoff to collection and integration teams. Each layer reduces downstream failure by making source decisions explicit, measurable, and repeatable. Web scraping services for ecommerce play a crucial role in gathering valuable market intelligence. By efficiently extracting product data, these services empower businesses to analyze competitors and optimize their pricing strategies. Additionally, they facilitate the collection of consumer reviews, which can inform product development and marketing efforts.
| Operating Layer | Core Responsibility | Enterprise Output |
| Source Discovery Layer | Identify relevant external source categories and specific source candidates | Structured source map aligned to business use cases |
| Source Qualification Layer | Evaluate relevance, authority, stability, coverage, freshness, and quality | Prioritized source inventory with qualification criteria |
| Access Feasibility Layer | Assess technical, operational, and refresh feasibility | Clear view of acquisition method, effort, and constraints |
| Governance Layer | Review source use, documentation, compliance considerations, and traceability | Controlled sourcing model with accountable decision records |
| Prioritization Layer | Rank sources by business value, risk, coverage, and implementation complexity | Roadmap for source activation and sequencing |
| Handoff Layer | Translate source decisions into collection, monitoring, and integration requirements | Pipeline-ready sourcing package for downstream teams |
Source Discovery Layer for Market and Signal Mapping
The source discovery layer identifies where relevant external signals exist. This includes public websites, industry databases, marketplaces, regulatory portals, government repositories, review platforms, product catalogs, trade sources, procurement platforms, media sources, specialist aggregators, and vendor datasets. However, discovery must be use-case led. The question is not what sources are available. The question is which sources explain the business problem. Strategic sourcing data requires mapping sources to decisions, metrics, operating teams, and expected downstream use.
Source Qualification Layer for Relevance, Stability, and Coverage
The source qualification layer evaluates whether a source deserves operational investment. Qualification should assess authority, coverage, freshness, update pattern, historical depth, structure, duplication risk, regional relevance, language complexity, and long-term stability. A source may be visible and technically accessible but still not valuable enough to maintain. Conversely, a difficult source may be essential because it provides unique coverage. Enterprise data sourcing requires a qualification discipline because every activated source creates downstream engineering, governance, and monitoring obligations.
Access Feasibility Layer for Technical and Operational Readiness
The access feasibility layer determines how a source can be used operationally. Some sources provide APIs. Others require structured web collection, document processing, portal navigation, feed integration, or vendor delivery. Feasibility also includes authentication requirements, update cadence, data format, rate constraints, structural volatility, and monitoring needs. This layer prevents unrealistic sourcing plans. A source is not ready for enterprise use simply because it contains useful data. It must be technically and operationally feasible to maintain.
Governance Layer for Compliance, Traceability, and Risk Control
The governance layer documents why a source is being used, what data is being accessed, which restrictions apply, what the intended use case is, and how source decisions are reviewed. This matters because external data sourcing can involve public information, licensed feeds, jurisdiction-specific datasets, personal data considerations, intellectual property questions, and contractual limits. NIST’s AI Risk Management Framework provides a risk management structure for AI systems, and the same logic applies to upstream data sources that feed analytics or AI workflows.
Prioritization Layer for Business Value and Use-Case Fit
The prioritization layer ranks sources according to business value, implementation complexity, risk, coverage contribution, and downstream impact. This prevents teams from activating sources simply because they are easy to access. At scale, the best source portfolio is not the largest portfolio. It is the portfolio that provides the strongest signal coverage for the decisions that matter. A data sourcing company should help define which sources are essential, which are supplemental, and which create unnecessary operational burden.
Handoff Layer for Collection, Integration, and Monitoring Teams
The handoff layer converts sourcing decisions into operational requirements. Collection teams need access methods, field expectations, refresh cadence, source priority, quality concerns, and failure indicators. Integration teams need schema expectations and downstream system requirements. Governance teams need documentation and review status. Monitoring teams need thresholds for source changes, downtime, or quality degradation. Without structured handoff, source discovery remains disconnected from execution. Data sourcing solutions become valuable when they reduce ambiguity before pipelines are built.
Enterprise Risks Created by Weak Data Sourcing Operations
Weak data sourcing creates enterprise risk because poor source decisions compound downstream. A pipeline can be well engineered and still produce poor intelligence if the sources are incomplete or unstable. A dashboard can be visually clear and still mislead decision-makers if the underlying source map excludes critical competitors, markets, or regulatory signals. Therefore, source risk should be evaluated before collection begins. The cost of weak sourcing is usually not visible immediately. It appears later through decision gaps, pipeline rework, compliance ambiguity, and scaling problems.
Strategic Blind Spots from Incomplete Source Coverage
Strategic blind spots emerge when source coverage does not reflect the full decision environment. A retailer may monitor only major marketplaces while missing regional competitors. A financial institution may track major regulatory bodies while missing local or sector-specific updates. An AI team may use convenient datasets that underrepresent critical edge cases. In each case, the organization acts on partial visibility. Source coverage analysis prevents incomplete external data sourcing from becoming a hidden constraint on strategy.
Poor Data Quality from Unqualified External Sources
Poor data quality often starts at the source. If a source is outdated, inconsistent, duplicated, biased, or structurally unstable, downstream validation can reduce but not fully eliminate the issue. Teams may spend significant effort cleaning data that should not have been prioritized in the first place. McKinsey’s 2025 global AI survey found that technology and data infrastructure practices contribute meaningfully to AI value creation, reinforcing that data foundations matter before advanced systems can scale.
Compliance Exposure from Unreviewed Source Selection
Compliance exposure increases when source selection is informal. Teams may collect or purchase data without fully documenting permitted use, retention expectations, access method, jurisdictional considerations, or contractual limitations. This risk becomes more significant when sourced data supports AI systems, automated decisions, regulated workflows, or executive reporting. Governance cannot be retrofitted easily after source use has expanded across teams. Enterprise data sourcing should therefore embed compliance review into source approval, not treat it as a later checkpoint.
Resource Drain from Repeated Source Discovery Work
Repeated source discovery drains analyst, engineering, and procurement resources. Different teams search for sources independently, evaluate similar vendors repeatedly, rebuild source inventories, and rediscover known limitations. This creates duplicated work and inconsistent standards. A governed source inventory reduces this waste by preserving institutional knowledge. It records which sources were evaluated, why they were accepted or rejected, how they can be accessed, what coverage they provide, and what risks are attached to their use.
Infrastructure Fragility from Unstable Source Dependencies
Infrastructure fragility appears when critical pipelines depend on sources that were never assessed for stability. A source may change structure, reduce access, alter update cadence, remove historical data, introduce authentication, or change licensing terms. If the enterprise has no fallback source, monitoring process, or source replacement plan, downstream systems become fragile. Public data sourcing and vendor-based sourcing both require continuity planning because source dependency risk increases as external data becomes operationally embedded.
Build vs Buy Decisions for Data Sourcing Services
The build versus buy decision for Data Sourcing Services should be evaluated as an infrastructure capability choice. Internal teams may own source discovery when the scope is narrow, the use case is familiar, and source complexity is limited. However, enterprise-scale sourcing requires a broader operating model: source mapping, vendor evaluation, public source assessment, access feasibility, governance review, prioritization, and handoff into acquisition pipelines. The right decision depends on whether the organization wants to own source discovery as a core capability or allocate part of that responsibility to a specialized partner.
| Evaluation Area | Internal Data Sourcing | Managed Data Sourcing Capability |
| Best Fit | Narrow use cases, familiar sources, limited market scope | Multi-market, multi-source, governed external data programs |
| Cost Profile | Lower visible start cost, higher hidden analyst and engineering burden | Structured cost with reusable sourcing methodology and accountability |
| Coverage | Depends on internal knowledge and available research time | Designed for systematic source mapping and gap analysis |
| Governance | Must be created and maintained internally | Embedded through documentation, review criteria, and source decision records |
| Scalability | Often becomes fragmented across teams | Supports expansion across regions, categories, use cases, and downstream systems |
When Internal Data Sourcing Operations Are Rational
Internal data sourcing operations are rational when the organization has strong domain knowledge, narrow source requirements, and limited operational dependency. For example, an internal team may manage sourcing for a small set of known competitor sites, a defined group of regulatory portals, or a short-term research project. Internal ownership can also make sense when source decisions are highly sensitive, proprietary, or directly tied to strategic planning. In these cases, the sourcing burden remains manageable, and risk exposure is contained.
Where Internal Source Discovery Breaks at Scale
Internal source discovery breaks when the scope expands across markets, languages, jurisdictions, source types, vendors, and use cases. What begins as research becomes a recurring infrastructure process. Analysts must assess coverage. Engineers must evaluate access methods. Legal teams must review terms and data use. Procurement must assess vendors. Data teams must translate sources into pipeline requirements. Deloitte’s 2025 Global Business Services Survey highlights how organizations are prioritizing agile, digital, and multifunctional service delivery models for efficiency, cost reduction, and enhanced customer experiences.
Total Cost Beyond Search, Research, and Initial Access
The total cost of data sourcing extends beyond finding sources. It includes source evaluation, coverage mapping, feasibility testing, governance documentation, vendor assessment, source monitoring, refresh planning, and replacement planning. It also includes the opportunity cost of analysts and engineers repeatedly investigating sources without a shared sourcing framework. In practice, business data sourcing becomes expensive when every new use case starts from zero. A managed sourcing model reduces repetition by creating reusable source intelligence.
Risk Allocation Across Sources, Governance, and Pipeline Readiness
Risk allocation determines who is responsible when a source fails, proves incomplete, creates compliance questions, or cannot scale technically. Internal sourcing concentrates that responsibility inside the organization. Managed sourcing distributes it through documented methodology, source qualification standards, governance review, and operational handoff. The decision should not focus only on cost. It should ask whether the enterprise can maintain source quality, coverage, documentation, and continuity as external data programs expand.
Source Lists vs Managed Data Sourcing Infrastructure
A source list is not infrastructure. It is an inventory. Managed data sourcing infrastructure goes further by evaluating each source for relevance, authority, coverage, accessibility, stability, compliance posture, technical feasibility, and downstream readiness. This distinction matters because many enterprise data programs begin with lists that appear useful but are not operationally actionable. The source layer must be designed to support collection, integration, governance, monitoring, and business use. Otherwise, the organization accumulates references rather than building capability.
Why Source Identification Is Not the Same as Source Readiness
Source identification means a team knows where data might exist. Source readiness means the source has been assessed for actual enterprise use. That includes whether the data is current, complete, relevant, accessible, permitted, stable, structured enough for extraction, and worth maintaining. A source can be identified in minutes, but requires extensive qualification before it supports production workflows. Data sourcing solutions create value by closing the gap between potential sources and operational sources.
The Operational Gap Between Discovery and Scalable Data Acquisition
The operational gap between discovery and acquisition is where many external data programs slow down. A business team may identify a valuable source, but engineering later discovers that access is unstable, the format is inconsistent, or the refresh cadence is unclear. Compliance may raise questions after development has started. Data teams may find that fields do not align with downstream schemas. Enterprise data sourcing reduces this risk by making operational readiness part of source evaluation before acquisition work begins.
Industry Applications of Data Sourcing Services
Industry applications vary because each sector depends on different external signals. Retail and e-commerce teams need pricing, assortment, product, marketplace, and promotion sources. Financial services teams need public filings, regulatory data, risk indicators, and alternative signals. AI and technology teams need source diversity for training, evaluation, enrichment, and product intelligence. Construction and public sector teams need procurement, permit, project, and regional development sources. The sourcing model remains consistent, but the source portfolio changes by industry.
Retail and E-Commerce Source Mapping
Retail and e-commerce data sourcing focuses on marketplaces, competitor websites, product catalogs, digital shelf data, promotions, reviews, availability signals, seller information, and regional price differences. The objective is to identify which sources provide the strongest coverage for pricing, assortment, demand, and category visibility. Practical outcomes include faster pipeline design, fewer gaps in competitor monitoring, better SKU coverage, and reduced manual research. Source quality is especially important because small coverage gaps can distort pricing or assortment decisions.
Financial Services and Risk Data Sourcing
Financial services sourcing requires careful qualification because external signals may support risk modeling, compliance monitoring, fraud detection, market intelligence, or counterparty analysis. Sources may include public records, court filings, sanctions lists, regulatory notices, corporate disclosures, market data, news, ownership records, and alternative signals. Governance is central. Source lineage, permitted use, update cadence, and documentation must be clear. In regulated environments, sourcing decisions can affect auditability as much as analytical performance.
AI and Technology Data Source Development
AI and technology teams use data sourcing to identify training data, evaluation datasets, product intelligence sources, documentation repositories, review platforms, support forums, code-related metadata, customer feedback channels, and external market indicators. Gartner’s 2025 data and analytics predictions also state that organizations prioritizing semantics in AI-ready data may significantly improve GenAI model accuracy and reduce costs, which reinforces the need to evaluate source semantics before data preparation begins.
Construction and Public Sector Opportunity Sourcing
Construction and public sector data sourcing focuses on tenders, procurement portals, permit records, planning applications, infrastructure announcements, award notices, contractor registries, supplier databases, and regional development sources. The operational value is early visibility. Firms can qualify opportunities faster, monitor bid pipelines, track regional investment, and evaluate competitor participation. Public sector sourcing also requires careful source coverage because valuable data is often distributed across local, regional, national, and specialized portals.
Business Outcomes from Enterprise Data Sourcing Infrastructure
The business value of enterprise data sourcing infrastructure should be measured by faster pipeline development, better source quality, lower compliance risk, reduced analyst and engineering burden, and more reliable scaling across markets and use cases. These outcomes depend on source complexity, use-case maturity, governance requirements, and downstream adoption. However, when the source layer is designed properly, the organization reduces rework before it occurs. This is why source infrastructure has commercial value even before data collection begins.
Faster Data Pipeline Development Through Qualified Sources
Pipeline development accelerates when source qualification has already been completed. Engineering teams receive source requirements, access feasibility, expected fields, refresh needs, and known constraints before development begins. This reduces back-and-forth between business, legal, data, and technical teams. In practical enterprise settings, qualified source packages can reduce early-stage pipeline scoping time by 20-40%, especially when teams previously relied on ad hoc research and informal source evaluation.
Better Data Quality Through Source-Level Validation
Data quality improves when weak sources are filtered before they enter the acquisition roadmap. Source-level validation evaluates authority, freshness, completeness, duplication risk, structural consistency, and relevance before engineering resources are committed. This prevents downstream systems from depending on sources that create repeated quality exceptions. Better source qualification also improves normalization because teams understand expected fields, taxonomies, identifiers, and gaps earlier in the process. Strong data sourcing is a quality control mechanism.
Lower Compliance Risk Through Governed Source Selection
Compliance risk declines when source selection is documented and reviewed before activation. Source governance should clarify intended use, data categories, jurisdictional considerations, access method, retention expectations, and any applicable contractual or policy constraints. OECD’s 2025 policy brief on data access and sharing in the age of AI emphasizes the need to balance data access with legal, technical, and organizational safeguards. That balance applies directly to external data sourcing.
Reduced Analyst and Engineering Burden
Analyst and engineering burden declines when source discovery, qualification, and handoff are systematized. Analysts no longer need to repeatedly search for the same source categories. Engineers no longer need to investigate feasibility without a business context. Legal and compliance teams no longer need to reconstruct source decisions after implementation has started. This reduces avoidable rework and allows specialized teams to focus on interpretation, architecture, risk review, and operational improvement rather than repetitive source investigation.
More Reliable Scaling Across Markets and Use Cases
Scaling becomes more reliable when the enterprise can extend a sourcing model across markets, languages, categories, and functions. A structured approach preserves source evaluation criteria while adapting to each use case. This matters because source complexity grows nonlinearly. Adding one new market may introduce new languages, portals, vendors, local regulations, taxonomies, and access constraints. Enterprise data sourcing creates a repeatable expansion model instead of forcing every team to invent its own approach.
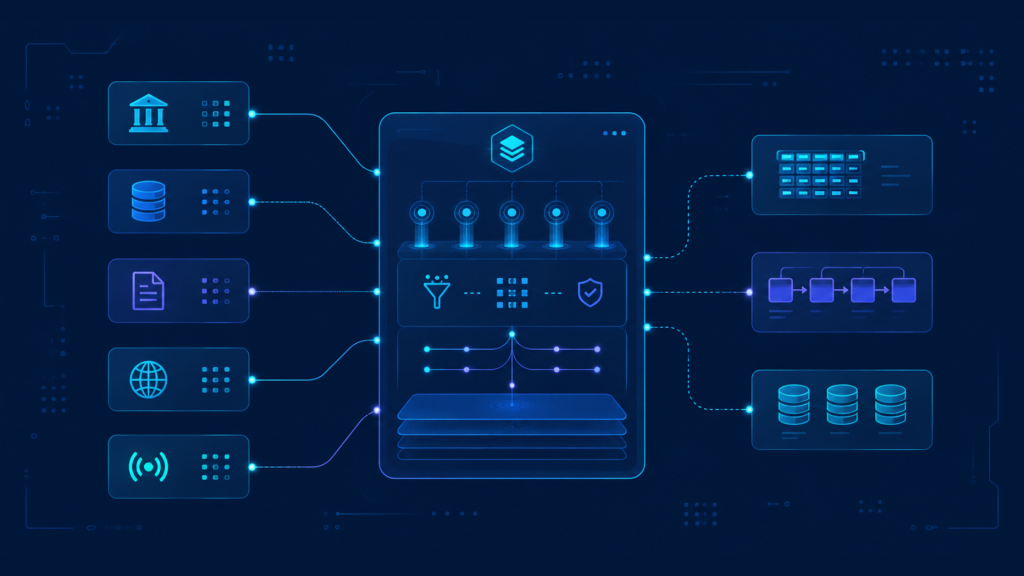
Data Sourcing Services as an Upstream Control Point
Data sourcing is an upstream control point because source decisions determine the quality, reliability, and risk profile of the entire external data program. Collection tools can retrieve data only from selected sources. Validation rules can check only the fields that sources provide. AI models can learn only from available training inputs. Business intelligence can compare only the markets and entities covered by the source portfolio. Therefore, source governance must precede pipeline governance, not follow it.
How Source Decisions Shape Data Architecture
Source decisions shape data architecture by determining data formats, refresh cadence, schema design, storage requirements, normalization logic, and monitoring needs. A portfolio dominated by APIs will have different architecture needs than one based on documents, portals, marketplaces, or unstructured web sources. Similarly, sources with high structural volatility require stronger monitoring and adaptation mechanisms. The sourcing layer, therefore, informs the technical design of data acquisition, data engineering, and delivery infrastructure.
Why Sourcing Discipline Improves Downstream Governance
Sourcing discipline improves downstream governance because it creates traceability before data enters operational systems. Teams can document source origin, business purpose, access method, evaluation criteria, and review status. This helps compliance, procurement, data governance, and AI governance teams understand why a source exists in the infrastructure. Gartner’s 2026 data and analytics predictions point toward the increasing importance of governance automation and machine-verifiable data contracts, which reinforces the need for structured source documentation.
How Enterprise Data Sourcing Supports AI, Analytics, and Automation
Enterprise AI, analytics, and automation depend on source foundations that are representative, current, traceable, and aligned with the intended decision context. Weak sourcing creates incomplete inputs, which then create weak features, unreliable dashboards, poor training data, and unstable automation. Data sourcing services support these systems by identifying which external signals matter, evaluating source suitability, and preparing sources for ongoing operational use. The result is not simply more data. It is a better external data supply.
AI Readiness Begins with Source Representativeness
AI readiness begins before labeling, feature engineering, or model training. It begins with whether the source portfolio represents the environment the model must understand. If sources underrepresent certain regions, categories, languages, behaviors, or edge cases, the model may perform well in tests but fail in production. McKinsey’s 2025 State of AI survey notes that only one-third of respondents report scaling AI across their organizations, while high performers are more likely to have strong practices across technology, data, operating model, and adoption.
Analytics Depend on Comparable Source Coverage
Analytics depend on comparable source coverage because decision-makers need consistent visibility across markets, competitors, products, and time periods. If one market has complete source coverage and another has partial coverage, comparisons become distorted. If some competitors are monitored through authoritative sources and others through weaker proxies, benchmark quality declines. Strategic sourcing data, therefore, requires source coverage mapping, source gap analysis, and normalization planning before analytics dashboards are built.
Automation Requires Reliable Source Continuity
Automation increases the cost of poor sourcing because systems act on incoming signals with less manual review. Pricing automation, risk alerts, AI retraining workflows, supplier monitoring, and market intelligence systems all depend on source continuity. If a critical source fails silently, automated workflows may continue operating on stale or incomplete data. Source continuity planning, fallback source identification, refresh monitoring, and source health checks are therefore essential components of a scalable external data infrastructure.
Commercial Evaluation Criteria for a Data Sourcing Company
Enterprise buyers should evaluate a data sourcing company by methodology, not by claims of access. The provider should demonstrate how sources are discovered, qualified, governed, prioritized, and handed off into data operations. It should also explain how it assesses source quality, feasibility, compliance exposure, and long-term maintainability. A sourcing partner that only provides source lists may create work for internal teams. A sourcing partner that creates infrastructure-ready source packages reduces friction across data, legal, procurement, and engineering functions.
Evidence of Structured Source Qualification
A serious data sourcing company should provide evidence of structured source qualification. This includes criteria for source authority, coverage, freshness, stability, field availability, update frequency, duplication risk, and operational complexity. The evaluation should show how each source contributes to the use case and how gaps are identified. Without this methodology, source selection becomes subjective. Enterprise buyers need confidence that sources are chosen for decision value, not convenience.
Governance and Documentation Standards
Governance and documentation standards should be visible in the sourcing process. Buyers should expect source records, review notes, intended use cases, access method documentation, compliance flags, and handoff requirements. These records help procurement and compliance teams evaluate source risk before acquisition begins. They also help data teams maintain source inventories over time. In this context, governance is not paperwork. It is the control layer that keeps sourcing decisions usable as the program scales.
Operational Handoff Quality
Operational handoff quality determines whether sourcing work becomes pipeline progress. A useful handoff should include source priority, access method, expected fields, refresh cadence, historical availability, known limitations, monitoring requirements, and downstream integration considerations. This allows collection teams to build efficiently and governance teams to review accurately. Poor handoff forces engineering teams to rediscover the source context. Strong handoff converts sourcing research into an executable external data infrastructure.
Conclusion: Data Sourcing Services as External Data Infrastructure
Data Sourcing Services have become an external data infrastructure because enterprise data programs now depend on source quality before collection, analytics, AI, or automation can succeed. The organizations that treat sourcing as informal research expose downstream systems to incomplete coverage, weak data quality, compliance ambiguity, and operational fragility.
The enterprise advantage is not access to the largest number of sources. It is the ability to identify, qualify, govern, prioritize, and operationalize the sources that matter for strategic decisions. Strong external data sourcing improves pipeline development, strengthens governance, reduces rework, and creates a more reliable foundation for business intelligence, AI development, pricing systems, market monitoring, and risk workflows.
Ultimately, a scalable external data infrastructure begins with disciplined sourcing. Enterprises that invest in source-level control build stronger foundations for data quality, decision speed, compliance readiness, and long-term external data operations.
Strategic Consultation for Enterprise Data Sourcing Readiness
A strategic consultation should clarify whether the organization’s current sourcing model can support its external data ambitions. Many enterprises already have dashboards, data teams, vendors, and collection tools, but still lack a governed source layer. The assessment should identify where source coverage gaps, quality issues, access constraints, duplicated research, compliance uncertainty, or weak handoff processes limit downstream data performance. The objective is to create clarity before investing further in collection or integration.
Assessing Source Coverage, Quality, and Governance Gaps
A sourcing readiness assessment should begin by mapping business use cases against required external signals. This includes identifying which markets, competitors, entities, public records, vendors, platforms, and source categories are needed for decision support. The assessment should then review source coverage, qualification criteria, governance documentation, technical feasibility, refresh requirements, and operational ownership. From there, leadership can distinguish a data collection problem from a source readiness problem.
Evaluating Internal, External, and Managed Data Sourcing Models
The final step is evaluating whether sourcing should remain internal, be supported by external specialists, or operate through a managed data sourcing model. The decision should consider source complexity, market coverage, compliance exposure, internal capacity, downstream dependency, and total cost of ownership. Submit an inquiry when the objective is to clarify the right sourcing model before allocating engineering resources, vendor budget, or external data infrastructure investment.


