
Key Takeaways
- Data Orchestration coordinates multi-stage market intelligence workflows across collection, validation, mapping, reconciliation, transformation, and delivery layers.
- Workflow orchestration systems reduce execution risk by managing pipeline dependencies, retries, schedules, backfills, and conditional logic.
- Dependency management ensures that market intelligence outputs are not published before the required upstream data and validation stages are complete.
- Pipeline scheduling supports batch, incremental, and event-driven execution models across time-sensitive market feeds.
- Reliable orchestration requires observability, lineage, audit logs, governance metadata, and controlled failure handling across the full data lifecycle.
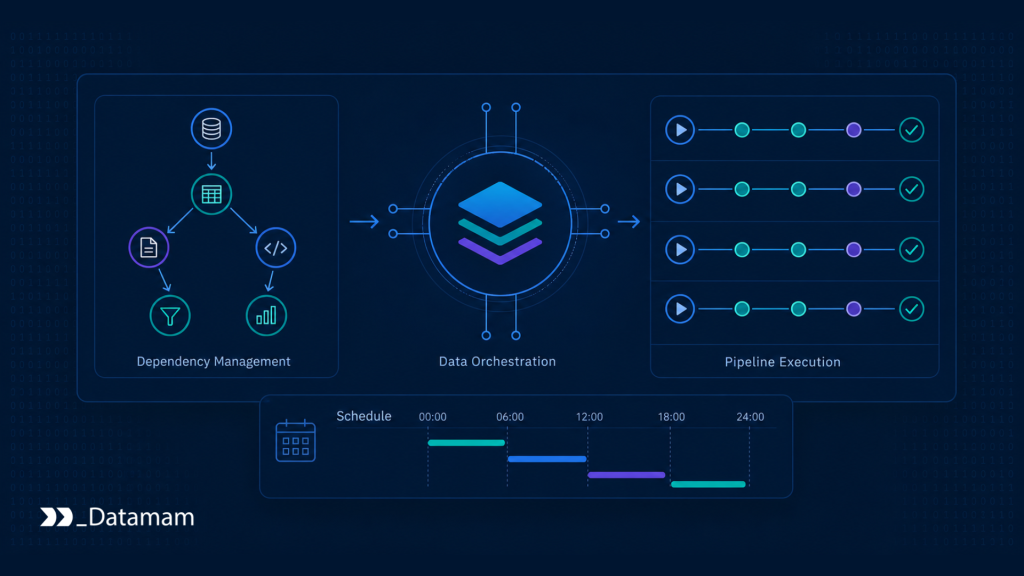
Market intelligence systems do not operate as single-step pipelines. A competitor price, product launch signal, assortment update, availability change, regulatory notice, or demand indicator may pass through multiple stages before it reaches a dashboard, forecast, report, or AI workflow. Each stage depends on the correct execution of earlier stages.
Data Orchestration provides the execution control layer that coordinates these workflows. It determines when pipeline stages run, which tasks depend on one another, what happens when a task fails, when data is safe to publish, and how downstream systems receive trusted outputs.
In enterprise market intelligence environments, orchestration is not simply scheduling. It is operational governance over complex data movement. Without it, pipelines may run out of order, publish incomplete outputs, miss source updates, or continue operating while silently producing unreliable intelligence.
Why Data Orchestration Matters in Market Intelligence Operations
Market intelligence operations depend on external sources that change independently and unpredictably. A source may update late, fail temporarily, introduce structural drift, or deliver partial records. Downstream systems still expect consistent outputs. Data Orchestration controls this complexity by coordinating pipeline execution across systems, stages, and dependencies.
Gartner’s 2025 data and analytics trends emphasize that data and analytics are becoming more widespread across organizations, while operational complexity and governance expectations are increasing. For market intelligence systems, that shift makes reliable pipeline execution a business requirement rather than an engineering preference.
External Market Feeds Require Coordinated Multi-Stage Execution
External market feeds typically require more than collection. A signal may need source validation, schema mapping, entity matching, discrepancy detection, reconciliation, enrichment, normalization, warehouse modeling, and delivery into dashboards or AI systems. These stages must run in the correct order.
For example, a competitor pricing feed should not be reconciled before entity matching completes. A dashboard should not publish updated market share metrics before all required regional feeds arrive. An AI feature table should not refresh before validation confirms that required fields are complete.
Data Orchestration provides this coordination. It defines the execution graph and ensures that each stage waits for the required upstream conditions. In practice, orchestration protects market intelligence from premature publication and inconsistent update timing.
Why Reliable Pipeline Execution Depends on Orchestration Control
Reliable pipeline execution depends on orchestration because market data workflows contain dependencies that cannot be managed safely with independent scripts or disconnected schedulers. A failure in one source can affect multiple downstream outputs. A delayed validation job can make a dashboard stale. A missed reconciliation stage can allow conflicting records into executive reporting.
Orchestration control creates a structured way to manage these dependencies. It tracks task status, execution timing, retries, failures, downstream effects, and completion criteria. It also provides metadata that helps teams investigate why a market intelligence output was delayed, incomplete, or inconsistent.
Without Data Orchestration, pipeline reliability depends on implicit assumptions. With orchestration, those assumptions become explicit execution rules that can be monitored, tested, and governed.
Operational Problems Created by Weak Orchestration
Weak orchestration often appears as timing inconsistency rather than complete failure. Pipelines may run, but not in the correct order. Dashboards may refresh, but before all source feeds are ready. AI workflows may update, but with missing data. Analysts may see conflicting numbers because dependent stages are executed on different schedules.
These problems are especially damaging in market intelligence systems because decisions depend on freshness and comparability. If one competitor’s feed is updated hourly and another is delayed, the resulting comparison may reflect pipeline timing rather than true market behavior.
When Pipeline Stages Run Out of Order or Without Dependency Awareness
A multi-stage pipeline can produce misleading outputs when stages run without dependency awareness. A transformation model may execute before source validation completes. A reconciliation job may process yesterday’s source state because the latest extraction failed. A warehouse table may update before all regional feeds have arrived.
These failures may not trigger obvious alarms. The system may produce outputs, but those outputs reflect incomplete or misordered execution. This creates a form of silent operational risk where data appears current but is not logically complete.
Dependency management prevents this by defining required upstream conditions. A task should know which feeds, validations, mappings, and reconciliations must be completed before it runs. If dependencies are missing or failed, the workflow should pause, retry, quarantine, or escalate instead of publishing unreliable intelligence.
How Scheduling Gaps Create Delayed, Incomplete, or Conflicting Market Intelligence
Pipeline scheduling determines when market intelligence is refreshed. Poor scheduling creates mismatched time windows, stale outputs, incomplete comparisons, and unnecessary processing overhead. A daily batch may be too slow for pricing intelligence, while unnecessarily high-frequency refreshes may waste compute on sources that rarely change.
Scheduling gaps also create coordination problems. If competitor feeds refresh at different times, a comparative report may combine new data from one source with old data from another. Also, if validation runs after publication, users may see unverified outputs. If backfills are not scheduled correctly, historical analysis may remain incomplete after recovery.
Pipeline scheduling must therefore reflect business cadence and source behavior. Some workflows require hourly execution. Others require event-driven triggers. Others can operate in daily or weekly cycles. Data Orchestration provides the control layer to manage these cadences coherently.
Designing Data Orchestration Layers for External Market Feeds
A well-designed orchestration layer defines how market intelligence workflows execute from source observation to final delivery. It coordinates tasks, dependencies, schedules, failure paths, backfills, retries, and publication rules. It should support both routine execution and exception scenarios.
The orchestration layer should also preserve execution metadata. Teams need to know when a workflow ran, which sources completed, which validations passed, which records were quarantined, which outputs were published, and which downstream assets were affected.
Coordinating Collection, Validation, Mapping, Reconciliation, and Delivery Stages
Market intelligence pipelines usually contain several operational stages. Collection retrieves source records. Validation checks completeness, structure, and plausibility. Schema mapping aligns source fields to target models. Reconciliation resolves conflicting records. Transformation prepares warehouse models. Delivery publishes outputs to dashboards, APIs, models, or reports.
Data Orchestration coordinates these stages as a controlled workflow. A collection task may trigger validation. Validation success may trigger mapping. Mapping completion may trigger reconciliation. Reconciliation output may trigger warehouse modeling. Publication may occur only after defined checks pass.
This staged execution prevents downstream systems from consuming intermediate or unverified records. It also makes failure handling more precise. If validation fails, the system can stop before reconciliation. If one regional feed is delayed, the workflow can publish unaffected regions or hold global outputs depending on business rules.
Dependency Management Across Sources, Transformations, and Downstream Outputs
Dependency management defines how sources, tasks, models, and outputs relate to one another. In market intelligence, dependencies can be technical and business-specific. A pricing model may require competitor prices, product mappings, currency rates, and regional availability. A market expansion dashboard may depend on product launches, category movement, competitor presence, and demand signals.
A mature orchestration layer maps these relationships explicitly. It knows which source feeds are required, which transformations depend on them, and which outputs consume the transformed data. If an upstream component fails, the system can identify the downstream impact.
This matters because market intelligence workflows often serve multiple stakeholders. One failed source may affect pricing dashboards but not product monitoring. Another may affect executive reporting but not raw research views. Dependency management allows teams to isolate impact rather than treating every issue as a system-wide failure.
Pipeline Scheduling for Batch, Incremental, and Event-Driven Market Workflows
Different market intelligence workflows require different execution cadences. Batch scheduling is suitable for lower-frequency signals such as weekly assortment summaries or monthly benchmark reports. Incremental workflows are better for signals that update frequently but can be processed as deltas. Event-driven workflows are needed when changes require rapid action, such as competitor price drops, product delistings, regulatory updates, or stock availability changes.
Pipeline scheduling should reflect the volatility of each signal and the decision window of each use case. A price change may need hourly or event-driven processing. A category taxonomy update may need controlled batch execution. A historical backfill may need separate scheduling to avoid interfering with production workflows.
IBM’s documentation for orchestration pipelines describes orchestration pipelines as workflows that schedule and perform tasks, including starting sequences of pipelines and jobs. That execution pattern aligns with enterprise market intelligence needs, where many dependent workflows must run in the right order and under controlled conditions.
Workflow Orchestration Systems in Enterprise Data Operations
Workflow orchestration systems provide the runtime control needed to operate complex data pipelines. They define task graphs, schedules, triggers, dependencies, retries, alerting, execution history, and operational metadata. In enterprise environments, they also support governance by making pipeline execution observable and reviewable.
For market intelligence teams, workflow orchestration systems help ensure that external signals move through the required controls before they become decision inputs. They create operational consistency across sources, markets, teams, and downstream systems. One critical aspect of maintaining this operational consistency is ensuring data accuracy in financial systems. Accurate data not only supports decision-making but also builds trust among stakeholders who rely on timely and precise information. As financial environments become increasingly complex, the importance of rigorous data validation and verification processes cannot be overstated.
Using Orchestration Metadata to Monitor Pipeline Execution
Orchestration metadata provides visibility into execution behavior. It shows which workflows ran, when they started, when they completed, which tasks failed, which retries occurred, and which downstream stages were affected. This metadata is essential for diagnosing reliability issues.
For example, if a pricing dashboard did not refresh, orchestration metadata can show whether the issue came from source collection, validation failure, delayed mapping, reconciliation backlog, warehouse transformation, or delivery. Without this metadata, teams must reconstruct pipeline behavior manually.
Execution metadata also supports performance analysis. Teams can identify slow tasks, unstable sources, recurring failures, missed schedules, and bottlenecks. Over time, this allows orchestration to become an optimization layer, not only a control layer.
Managing Retries, Backfills, Failures, and Conditional Execution Logic
External market pipelines require controlled failure handling. Sources may be temporarily unavailable. Data may arrive late. Validation may fail. A mapping rule may break after source structure changes. If every failure requires manual intervention, operations become fragile. If failures are ignored, outputs become unreliable.
Workflow orchestration systems manage retries, backfills, and conditional logic. A failed source collection may retry with adjusted timing. A delayed feed may trigger a partial workflow. A corrected mapping rule may require a historical backfill. A high-severity validation failure may stop publication and escalate to the responsible team.
Conditional execution is especially important. Not every workflow should behave the same way after failure. A low-risk missing review count may not block publication. A missing competitor price field may block pricing intelligence. Orchestration allows these decisions to be encoded as controlled execution rules.
Reliability Controls in Orchestrated Market Intelligence Pipelines
Reliability in market intelligence operations requires more than uptime. A pipeline can be available and still produce incomplete, stale, or logically inconsistent outputs. Reliability controls must therefore verify execution order, data freshness, completeness, validation status, and downstream publication readiness.
Data Orchestration provides the framework for applying these controls consistently. It ensures that operational checks happen at the right stages and that failures are handled before they affect decision systems.
Preventing Silent Failures Across Multi-Stage Data Flows
Silent failures occur when workflows appear successful while producing unreliable results. A task may be completed, but collect fewer records than expected. A transformation may run, but use stale upstream data. A reconciliation step may publish outputs despite unresolved exceptions. A dashboard may update while missing one region or competitor group.
Preventing silent failures requires more than checking task completion. Orchestration should include data-aware checks such as record count thresholds, freshness checks, validation gates, null-rate monitoring, source availability checks, and output completeness requirements.
NIST’s current AI Risk Management Framework reinforces the need for governance and risk management practices in systems that influence decisions. For market intelligence pipelines that feed AI workflows or automated recommendations, orchestration controls help ensure that upstream failures are detected before unstable inputs reach decision systems.
Maintaining Data Freshness, Execution Order, and Output Completeness
Freshness, order, and completeness are core reliability dimensions. Freshness confirms that outputs reflect current source states. Execution order confirms that the required controls were completed before publication. Completeness confirms that expected sources, markets, entities, and fields are present.
An orchestration layer should track freshness by source, dataset, and output. It should enforce execution order through dependency graphs. It should verify completeness through validation thresholds before downstream delivery. If these controls fail, the workflow should route outputs to quarantine, delay publication, or issue alerts.
This matters for market intelligence because stale or partial data can create false strategic interpretation. A competitor may appear inactive because their feed failed. A regional market may appear stable because one source was not refreshed. Orchestration reduces these risks by making pipeline readiness explicit.
Technology Stack Behind Enterprise Data Orchestration
Enterprise data orchestration depends on coordinated technologies that manage workflow execution, event movement, transformation, storage, observability, lineage, and governance. The stack should support both operational reliability and enterprise reviewability.
In practice, orchestration systems interact with data collection frameworks, streaming platforms, processing engines, transformation tools, warehouses, observability systems, and metadata catalogs. The goal is to make pipeline execution controlled, traceable, and resilient. Understanding data lineage in complex systems is essential for ensuring transparency and accountability in data-driven decisions. By accurately tracking the flow of data through various components, organizations can identify sources of errors and ensure compliance with regulations. This comprehensive view allows teams to respond to issues promptly, optimizing both performance and reliability across the entire data infrastructure.
Airflow for Workflow Orchestration and Dependency Management
Apache Airflow is commonly used to define directed workflow graphs, manage dependencies, schedule jobs, and monitor execution. In market intelligence operations, Airflow can coordinate collection jobs, validation tasks, mapping workflows, reconciliation processes, warehouse transformations, and downstream publication.
Airflow’s value is not only scheduling. It gives teams visibility into task dependencies and execution status. It allows workflows to pause when upstream checks fail, retry when transient errors occur, and trigger downstream tasks only when required conditions are met.
For external market feeds, this prevents isolated scripts from becoming hidden operational dependencies. Workflow logic becomes visible, testable, and maintainable.
Kafka, Spark, dbt, and Warehouse Layers for Coordinated Data Movement
Apache Kafka supports event-driven market intelligence workflows by routing detected changes into downstream consumers. A competitor price change, product launch, availability update, or regulatory signal can trigger specific processing paths rather than waiting for a fixed batch schedule.
Apache Spark supports distributed processing for high-volume transformations, entity matching, reconciliation, and enrichment. dbt structures transformation logic in the warehouse, making analytical models more consistent and documented. Snowflake, BigQuery, and Databricks provide storage and processing environments for raw, staged, reconciled, and published datasets.
Together, these systems support coordinated data movement across the pipeline. Orchestration determines when and how tasks run. Streaming moves events. Processing transforms records. Warehouse models expose trusted outputs. Each layer must be connected through metadata and dependencies.
Observability, Lineage, Audit Logs, and Governance Metadata
Observability tools such as Prometheus can monitor pipeline latency, failure rates, retry counts, task duration, event volume, data freshness, and output completeness. Validation systems such as Great Expectations can enforce quality gates before data is published.
Lineage systems connect execution metadata to data movement. They show which source feeds produced which datasets, which transformations were applied, and which dashboards or models consume the results. Audit logs preserve workflow changes, manual overrides, failure resolutions, and publication history.
IBM’s 2025 updates to orchestration pipelines in watsonx reference improvements to pipeline execution speed, reinforcing that orchestration is an active enterprise capability for automating and managing complex data and AI workflows.
Governance and Compliance Value of Data Orchestration
Data orchestration supports governance by creating reviewable execution records. It shows when workflows ran, which controls passed, where failures occurred, which outputs were produced, and how exceptions were handled. This visibility matters when market intelligence supports strategic decisions, regulatory monitoring, commercial actions, or AI-enabled workflows.
Governance requires more than knowing that data exists. Teams need to know whether the process that produced the data was controlled. Orchestration metadata provides that evidence.
Creating Reviewable Execution Records Across Market Data Pipelines
Reviewable execution records allow teams to reconstruct pipeline behavior. If a dashboard value is questioned, teams can inspect whether upstream collection was completed, whether validation passed, whether reconciliation resolved discrepancies, whether transformations ran on current inputs, and whether publication occurred successfully.
This is important for audit readiness and internal accountability. Market intelligence outputs may influence pricing, product launches, competitive response, demand planning, or board reporting. When those outputs matter, the organization must be able to explain how they were produced.
Execution records should include timestamps, task status, input datasets, output datasets, validation results, retry events, exceptions, overrides, and publication state. These records transform orchestration from an engineering convenience into a governance asset.
Managing Cross-Border, Source-Specific, and Access-Controlled Workflow Dependencies
Market intelligence workflows often span regions, platforms, and data access conditions. Some sources may be region-specific. Some workflows may include access-controlled datasets. While some outputs may have retention, access, or jurisdictional considerations. Orchestration must respect these constraints.
For example, a workflow may need to process European market feeds separately from U.S. feeds because of source rules, language models, or compliance review. Access-controlled data may require separate publication paths. Certain outputs may be visible only to approved teams.
OECD’s 2025 Digital Government Index describes digital government maturity in terms of strategies and initiatives that leverage data and technology across institutions. For enterprises, the same operational principle applies: complex data workflows need coordinated governance, not isolated execution.
You can run an external data infrastructure audit with our team to review your current setup and understand what is required to build a reliable, enterprise-scale external data infrastructure.
Data Orchestration as Market Intelligence Infrastructure
Data orchestration becomes market intelligence infrastructure when it controls the execution of external data workflows across the full lifecycle. It connects source monitoring, validation, mapping, reconciliation, transformation, delivery, and governance into one managed operating model.
At scale, this matters because market intelligence systems serve multiple stakeholders with different timing requirements. Pricing teams need rapid updates. Product teams need consistent launches and assortment views. Strategy teams need reliable trend analysis. AI teams need stable feature pipelines. Orchestration ensures these workflows execute with the right dependencies and controls. To support these diverse needs, leveraging market analysis tools for enterprises becomes essential. These tools enable organizations to assess data trends effectively and make informed decisions quickly. By integrating advanced analytics and real-time insights, companies can respond proactively to market dynamics and maintain a competitive edge.
Strengthening Pricing, Product, Competitor, and Demand Intelligence Workflows
Pricing intelligence depends on timely competitor feeds, validated price fields, reconciled product matches, and complete regional coverage. Product intelligence depends on launch detection, category mapping, variant resolution, and historical state tracking. Competitor intelligence depends on coordinated source updates and consistent entity models. Demand intelligence depends on stable signals such as review velocity, availability movement, stock changes, and search visibility.
Data Orchestration strengthens these workflows by ensuring that each output is produced only after the required upstream stages are complete. It also supports differentiated execution cadences. A pricing workflow may run hourly, while a product taxonomy workflow may run daily. A demand signal workflow may combine event triggers with scheduled aggregation.
This coordination keeps market intelligence aligned with business decision timing. Teams receive outputs that are not only current but operationally complete.
Building Long-Term Operational Trust Through Controlled Pipeline Execution
Long-term trust depends on repeatable execution. Market intelligence systems evolve as sources change, markets expand, models improve, and new use cases emerge. Without orchestration, pipeline logic becomes fragmented across scripts, schedules, manual dependencies, and undocumented operational knowledge.
Controlled orchestration reduces that fragility. It makes workflows visible, dependencies explicit, failures recoverable, and execution history reviewable. It also reduces dependence on individual operators because the workflow itself documents how market intelligence is produced.
As a result, Data Orchestration supports institutional trust. Teams can understand how workflows run, why outputs were delayed, where failures occurred, and which downstream systems were affected. That visibility is essential when market intelligence becomes part of the enterprise decision infrastructure.
Conclusion: Turning Complex Market Data Workflows into Reliable Intelligence Operations
Market intelligence systems depend on complex data movement. External signals must be collected, validated, mapped, reconciled, transformed, modeled, delivered, and governed before they can support decisions. Each stage introduces dependencies, timing constraints, and failure risks.
Data Orchestration provides the control layer that makes these workflows reliable. It manages workflow orchestration systems, dependency management, pipeline scheduling, retries, backfills, conditional logic, observability, lineage, and governance metadata across multi-stage data operations.
For enterprises using market intelligence to support pricing, product strategy, competitive benchmarking, demand forecasting, regulatory monitoring, or AI workflows, orchestration is not a background technical function. It is the execution discipline that keeps intelligence systems trustworthy under operational complexity.
A structured review can help evaluate whether current market intelligence workflows have reliable orchestration controls, dependency management, scheduling logic, failure handling, freshness checks, and audit-ready execution records. You can run an external data infrastructure audit with our team to review your current setup and understand what is required to build a reliable, enterprise-scale external data infrastructure.


