Key Takeaways
- Data Lineage Systems help enterprises trace external market signals from source origin to final intelligence output.
- End-to-end lineage strengthens trust by showing how raw data changes across collection, mapping, validation, transformation, and delivery stages.
- Pipeline impact analysis helps teams understand which dashboards, models, reports, and workflows are affected before changes are deployed.
- Data flow traceability reduces operational ambiguity when market intelligence outputs are questioned or audited.
- Reliable lineage requires metadata capture, audit logs, governance controls, and field-level visibility across the full data lifecycle.
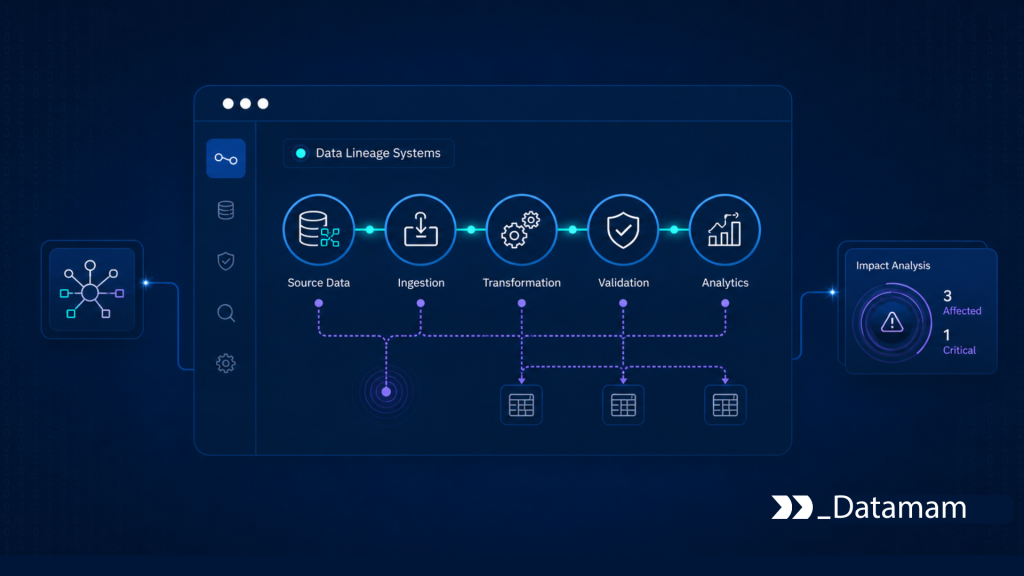
Market intelligence systems rarely move data through a single clean path. A competitor price, product listing, review signal, regulatory update, or availability change may pass through collection, normalization, schema mapping, validation, enrichment, transformation, warehouse modeling, dashboarding, and AI workflows before it becomes a decision input. Each stage changes the data in some way.
Data Lineage Systems make that movement visible. They show where a signal originated, how it moved, which transformations were applied, which systems consumed it, and which business outputs depend on it. In multi-stage market intelligence operations, lineage is not documentation after the fact. It is an operational control.
Without lineage, teams may know what a dashboard says but not why it says it. They may see a market signal without knowing its source, freshness, transformation path, or confidence level. At enterprise scale, that gap weakens trust, slows investigation, and increases governance risk.
Why Data Lineage Systems Matter in Market Intelligence Operations
Market intelligence depends on external signals that are structurally unstable, source-controlled, and often commercially ambiguous. Unlike internal transactional systems, external market sources do not follow a single schema or governance model. Each source may change structure, update frequency, field meaning, or access pattern without notice.
As a result, Data Lineage Systems provide the traceability needed to convert fragmented external signals into a trusted business context. Gartner’s 2025 data and analytics trends note that data and analytics are spreading across organizations while raising new governance and operational challenges. That shift makes lineage essential because more teams are consuming data, more systems depend on it, and more decisions require explainability.
External Market Data Moves Through Multiple Transformation Stages
External market data is rarely usable in its raw form. A product price collected from a marketplace may need source authentication metadata, currency normalization, regional tagging, seller classification, promotion detection, timestamp correction, entity matching, and warehouse modeling before it becomes part of a pricing intelligence dashboard.
Each stage introduces potential interpretation. A raw source field may be renamed, split, joined, converted, filtered, enriched, or mapped to an internal taxonomy. These transformations are necessary, but they also create risk if they are not traceable. A final metric may look authoritative while hiding important assumptions made upstream.
End-to-end lineage solves this by preserving the movement from source observation to final output. It allows engineers, analysts, and business users to see how a market signal changed across stages rather than treating the final table or dashboard as an isolated truth.
Why Untraceable Data Flows Weaken Trust in Market Intelligence
Untraceable data flows weaken trust because teams cannot explain the relationship between source reality and analytical output. If a competitor price appears incorrect, a business user needs to know whether the issue came from the source, collection layer, schema mapping logic, currency conversion, deduplication rule, warehouse model, dashboard filter, or AI feature pipeline.
Without lineage, investigation becomes manual and slow. Teams search logs, inspect scripts, compare source pages, question data owners, and reconstruct pipeline behavior after the fact. This delays decision-making and creates friction between market-facing teams and data teams.
Data flow traceability changes the operating model. Instead of asking who touched the data, teams can inspect how the data moved. That visibility is especially important when market intelligence supports pricing, product planning, board reporting, regulatory monitoring, or AI-assisted decision workflows.
Operational Risks Created by Missing Lineage
Missing lineage rarely causes a single visible failure. Instead, it creates uncertainty across operations. Reports may be correct, but teams cannot prove why. Models may perform well, but engineers cannot explain which input change caused a shift. Dashboards may disagree, and analysts may not know which pipeline version produced each result.
In market intelligence systems, this uncertainty becomes more serious because external data is volatile. Sources change frequently, mappings evolve, and downstream users interpret signals under time pressure. Without lineage, the organization loses the ability to separate true market change from pipeline behavior.
When Teams Cannot Explain Where a Market Signal Came From
A common problem occurs when teams see a market signal but cannot trace its origin. A dashboard may show that a competitor reduced prices in a region, but the team may not know which marketplace page, seller feed, regional variant, collection timestamp, or transformation rule produced the metric.
This creates operational ambiguity. If the signal is real, leadership may need to respond quickly. If it is a mapping error, reacting would be costly. Without source traceability, teams must spend time verifying the signal manually before acting.
Data Lineage Systems reduce this ambiguity by connecting each output to source-level evidence. A market signal should be traceable to its source system, raw record, collection time, processing job, mapping rule, validation result, and downstream model. That trace allows teams to verify intelligence before making decisions.
How Broken Traceability Affects Reporting, Analytics, and AI Outputs
Broken traceability affects every layer that consumes data. In reporting, teams may struggle to reconcile differences between dashboards. In analytics, historical trends may shift without a clear explanation. Also in AI workflows, feature behavior may change because upstream mappings, filters, or entity resolution rules changed without documentation.
NIST’s AI Risk Management Framework, updated as a live resource and expanded with recent guidance for AI risk contexts, reinforces the importance of structured governance and oversight for systems that influence decisions. For market intelligence operations that feed AI models or automated workflows, lineage provides a practical mechanism for understanding how inputs were sourced, transformed, and used.
If a model begins recommending different pricing actions, teams need to know whether market behavior changed or whether the input pipeline changed. End-to-end lineage provides the evidence needed to make that distinction.
Designing End-to-End Lineage for External Market Feeds
End-to-end lineage must be designed into the architecture, not added as a manual documentation layer after deployment. It requires metadata capture at each pipeline stage, consistent entity identifiers, transformation tracking, field-level mapping history, and links between technical operations and business outputs.
In external market feeds, lineage should answer four questions: where did the data come from, what happened to it, where did it go, and what decisions or systems depend on it. A useful lineage model must support both technical debugging and business accountability. In external data strategies in gaming, it is crucial to establish clear protocols for tracking data flow and usage across various platforms. This transparency not only enhances player experience but also ensures compliance with regulatory standards within the industry. By implementing robust data governance practices, developers can optimize performance while safeguarding user trust and rewarding engagement.
Tracking Source Origin Across Collection, Mapping, and Transformation Layers
Source origin tracking begins at collection. Each record should capture source identity, URL or endpoint context where applicable, collection timestamp, geographic context, session or access context, and collection method. For market intelligence, source origin is not just a technical detail. It affects confidence. A brand-owned source, reseller listing, marketplace seller, public filing, and aggregator feed may carry different levels of authority.
The mapping layer then records how source fields were interpreted. A source field called offer_price may map to discounted_price, current_price, or promotional_price depending on source logic. Without mapping metadata, downstream teams cannot know which business concept the field represents.
Transformation lineage then records normalization, enrichment, deduplication, filtering, and aggregation steps. This creates a continuous path from raw signal to standardized market intelligence output.
Preserving Transformation History from Raw Signals to Intelligence Outputs
Transformation history shows how data changes as it moves through the system. In a multi-stage pipeline, the same market signal may be cleaned, normalized, enriched, matched to an entity, merged with other sources, modeled in a warehouse, and exposed through dashboards or APIs.
Each transformation should produce metadata that explains the rule applied, the job or model responsible, the execution time, the input dataset, and the output dataset. When transformation logic changes, lineage should preserve version history so teams can interpret shifts in historical reporting.
This is especially important for market intelligence because minor changes can affect strategic interpretation. A revised category mapping may make a competitor appear to expand faster. A new deduplication rule may change market share estimates. A lineage system helps teams distinguish actual market movement from pipeline logic changes.
Connecting Lineage Metadata to Business Context and Decision Use
Technical lineage alone is not enough. Enterprise users need to understand which market intelligence outputs depend on each data flow. A field-level lineage graph may show that product_price feeds a dbt model, but business users need to know that the model supports competitor pricing dashboards, margin simulations, executive scorecards, or AI pricing recommendations.
Connecting lineage metadata to business context requires a data catalog, semantic layer, business glossary, or metadata system that links technical assets to business definitions. Terms such as competitor price, availability status, promotional depth, product launch date, and seller authority should be defined consistently.
This business context turns lineage from an engineering tool into an enterprise trust system. It helps commercial, compliance, and leadership teams understand how data supports decisions.
Data Flow Traceability Across Multi-Stage Pipelines
Data flow traceability tracks movement through systems, jobs, models, storage layers, and outputs. In a market intelligence environment, data may move through browser automation, ingestion queues, orchestration workflows, distributed processing, validation systems, warehouse models, BI dashboards, and AI feature stores.
The goal is not to create diagrams for documentation. The goal is to make the investigation possible. When something changes, fails, or produces an unexpected result, traceability allows teams to find the affected stage quickly and understand the downstream consequences. Effective data orchestration for efficient workflows enhances the overall agility of the data pipeline, enabling teams to respond swiftly to emerging insights. By optimizing these workflows, organizations can ensure that critical data flows seamlessly from one stage to another, minimizing delays and maximizing accuracy. Consequently, this streamlined approach not only improves operational efficiency but also empowers data-driven decision-making across all business units.
Tracing Data Movement Through Orchestration, Processing, and Warehouse Layers
Modern market intelligence pipelines often use orchestration systems such as Airflow to coordinate collection, validation, transformation, and delivery. Airflow metadata can show which jobs ran, which dependencies existed, where failures occurred, and which downstream tasks were affected.
Processing frameworks such as Spark generate execution history for transformation jobs. Streaming systems such as Kafka preserve event movement across topics and consumers. Warehouse systems such as Snowflake, BigQuery, and Databricks store structured outputs, historical states, and transformation models.
Data flow traceability connects these layers. A record collected from an external source should be traceable through ingestion, processing, warehouse modeling, and final consumption. If one layer changes, teams should understand what was affected downstream.
Maintaining Field-Level Traceability Across Pricing, Product, and Competitor Signals
Field-level traceability is essential because market intelligence decisions often depend on individual attributes. A competitor pricing dashboard may depend on base price, sale price, shipping cost, seller name, availability status, region, and timestamp. Each field may originate from a different source or transformation rule.
If a pricing output looks wrong, record-level lineage may not be enough. Teams need to know which specific field changed, how it was mapped, whether it was normalized, and which downstream calculations used it. This is particularly important when fields are derived. Promotional depth may be calculated from the list price and sale price. Availability confidence may combine stock status, delivery time, and seller signals.
Field-level lineage allows teams to trace these dependencies precisely. It reduces the time required to investigate quality issues and improves confidence in market-facing outputs.
Pipeline Impact Analysis in Market Intelligence Systems
Pipeline impact analysis helps teams understand the downstream effects of a proposed change before it is deployed. In multi-stage operations, a small upstream adjustment can affect many outputs. Changing a schema mapping rule, removing a field, updating a transformation model, or modifying a validation threshold may alter dashboards, reports, AI features, and downstream workflows.
Impact analysis is, therefore, a planning and risk-control capability. It prevents teams from treating pipeline changes as isolated technical updates when they may affect business interpretation.
Identifying Downstream Effects Before Pipeline or Schema Changes
Before changing a pipeline, teams need to know which assets depend on the affected dataset or field. If a source field is renamed, which models depend on it? What if a validation rule becomes stricter, which dashboards may show lower record counts? If a category taxonomy changes, which trend analyses, product comparisons, and executive reports will shift?
Pipeline impact analysis answers these questions by using lineage metadata to map upstream and downstream dependencies. It allows data teams to assess risk before deployment, notify affected stakeholders, and test outputs that matter most.
IBM’s 2025 announcement on data protection and governance services highlights customer emphasis on data life-cycle management, lineage, provenance, privacy mapping, and governance capabilities in enterprise environments. That reflects a broader market reality: organizations need visibility into data dependencies because data systems now influence security, privacy, operations, and AI outcomes through interconnected workflows.
Understanding Which Dashboards, Models, and Reports Depend on Each Data Flow
Market intelligence systems often serve many stakeholders. Pricing teams use competitive price feeds. Product teams use assortment and launch signals. Strategy teams use market expansion indicators. Executives use aggregated scorecards. AI teams use structured features. A single upstream dataset may feed all of these outputs.
Without lineage, teams may not know who depends on a data flow until something breaks. With lineage, they can identify affected dashboards, warehouse models, reports, APIs, and machine learning features in advance.
This improves change management. Teams can test critical outputs, communicate expected changes, and prevent unexpected shifts in leadership reporting. Pipeline impact analysis is therefore not only an engineering practice. It is a governance process that protects organizational trust in market intelligence.
Technology Stack Behind Enterprise Data Lineage Systems
Enterprise lineage systems rely on metadata capture across orchestration, processing, storage, transformation, observability, and governance layers. No single tool provides complete lineage unless the architecture is designed to consistently capture and connect metadata.
In practice, lineage systems combine metadata from Airflow, Kafka, Spark, dbt, Snowflake, BigQuery, Databricks, observability systems, catalogs, and governance platforms. The objective is to create a connected view of how data moves and changes.
Orchestration Metadata from Airflow and Processing History from Spark
Airflow provides workflow metadata that supports operational lineage. It shows task dependencies, execution status, retry behavior, scheduling logic, and failure points. In market intelligence systems, this helps teams determine whether a missing output resulted from a collection failure, a validation failure, a transformation delay, or a downstream delivery issue.
Spark provides processing history for distributed transformations. It can show which jobs processed which inputs, which outputs were produced, and when large-scale transformations ran. This is useful when market datasets require entity matching, taxonomy normalization, aggregation, or enrichment across high-volume sources.
Together, orchestration metadata and processing history provide the operational backbone for lineage. They show how data moved through execution layers, not only how tables relate in a warehouse.
Warehouse Lineage Across Snowflake, BigQuery, and Databricks
Warehouse and lakehouse platforms are where many lineage questions become business-critical. Snowflake, BigQuery, and Databricks often store raw tables, staged tables, transformed models, historical versions, and analytical outputs. DBT models may define dependencies between these layers.
Warehouse lineage should show table-level, column-level, and model-level dependencies. If a pricing metric depends on competitor_price_normalized, teams should be able to trace that field back to the source price, currency conversion logic, region rules, promotion handling, and validation checks.
This is where end-to-end lineage becomes practical. It connects raw source data to modeled intelligence outputs and enables teams to explain how final business metrics were produced.
Observability, Audit Logs, and Governance Metadata Across Data Flows
Observability systems such as Prometheus can track pipeline health, latency, event volumes, freshness, and failure patterns. Validation systems such as Great Expectations can record whether datasets passed quality checks. Audit logs can preserve who changed mapping rules, transformations, access permissions, or publication settings.
Governance metadata connects technical lineage to ownership, policy, classification, retention, access, and compliance requirements. A field may be technically traceable, but governance metadata explains who owns it, how it can be used, and which controls apply.
OECD’s 2025 Digital Government Index and Open, Useful and Re-usable Data Index emphasize coherent digital foundations and reusable data policies. The same operating principle applies inside enterprises: data becomes more valuable when it can be traced, understood, reused, and governed across systems.
Governance and Compliance Value of Data Lineage Systems
Lineage supports governance by making data movement explainable. It shows where the data came from, how it changed, who accessed it, which controls applied, and which outputs used it. This matters for audit readiness, compliance review, AI governance, procurement evaluation, and internal risk management.
In market intelligence operations, governance is not limited to sensitive personal data. It also includes source accountability, data usage control, access restrictions, retention, transformation transparency, and cross-border data considerations.
Supporting Audit Readiness and Source Accountability
Audit readiness depends on evidence. If a market intelligence output influences a commercial decision, teams may need to explain the source and transformation path behind it. This is especially true when outputs support pricing decisions, vendor negotiations, investment analysis, compliance monitoring, or AI-assisted recommendations.
Data Lineage Systems provide that evidence. They help teams answer where the data originated, whether it passed validation, which transformations were applied, which sources were combined, and which output consumed the result.
Source accountability is equally important. External market intelligence often combines multiple sources with different authority levels. Lineage allows teams to preserve source-specific context rather than treating all inputs as interchangeable. This protects against overreliance on low-confidence sources and supports defensible decision-making.
Managing Cross-Border, Source-Specific, and Access-Controlled Data Flows
Market intelligence may span jurisdictions, languages, platforms, and regulatory environments. Cross-border operations introduce variation in data availability, permitted use, retention expectations, contractual constraints, and access policies. Lineage helps teams understand how data moves across these boundaries.
Access-controlled data flows also require traceability. Teams need to know which systems processed restricted fields, which users accessed outputs, and whether derived datasets inherit control requirements. This is especially important when external signals are combined with internal commercial data.
Lineage does not replace legal or compliance review. However, it provides the operational evidence that makes review possible. Without traceability, governance teams must rely on assumptions. With lineage, they can evaluate actual data movement.
You can run an external data infrastructure audit with our team to review your current setup and understand what is required to build a reliable, enterprise-scale external data infrastructure.
Data Lineage as Market Intelligence Infrastructure
Data lineage becomes infrastructure when it is embedded across market intelligence operations rather than maintained as occasional documentation. It supports debugging, trust, governance, impact analysis, executive confidence, and AI reliability.
At scale, market intelligence teams need to answer questions quickly. Why did this metric change? Which source produced this signal? Which dashboard depends on this field? Did a pipeline update affect last month’s report? Which model consumes this dataset? Data Lineage Systems make those answers accessible. By leveraging market insights for enterprise decisions, organizations can enhance their strategic acumen and respond to market dynamics with agility. This proactive approach not only informs leadership but also aligns team efforts toward shared objectives. Ultimately, the integration of these insights leads to more informed, data-driven outcomes that resonate across all levels of the business.
Strengthening Confidence in Executive Reporting and Competitive Intelligence
Executive reporting requires trust. Leadership teams may not need to inspect every transformation, but they need confidence that market intelligence is traceable when challenged. If a competitor benchmark, pricing trend, market expansion signal, or demand indicator appears in a leadership context, teams must be able to defend its origin and calculation path.
Lineage strengthens that confidence by making the intelligence chain visible. It allows market-facing teams to move from “the dashboard says this” to “this signal came from these sources, passed these validations, was transformed through these rules, and feeds these outputs.”
That distinction matters in procurement, board reporting, and strategic planning. Market intelligence becomes more credible when it is supported by traceable operations.
Building Long-Term Operational Trust Across Multi-Stage Data Systems
Long-term trust depends on consistency. Multi-stage data systems evolve constantly: sources change, schemas drift, mappings improve, models are refactored, warehouses are reorganized, and dashboards are revised. Without lineage, every change introduces uncertainty.
Lineage provides continuity across that evolution. It preserves context as systems change, helping teams understand whether a shift in output reflects real market movement or a pipeline modification. It also reduces dependency on individual engineers or analysts because institutional knowledge is captured in metadata rather than memory.
Ultimately, lineage turns complex data movement into manageable infrastructure. It gives organizations a way to operate market intelligence systems with confidence, even as sources, teams, and use cases expand.
Conclusion: Turning Complex Data Movement into Traceable Market Intelligence
Multi-stage market intelligence operations depend on trust. External signals must be collected, mapped, validated, transformed, modeled, delivered, and interpreted before they can support decisions. Every stage adds value, but every stage also creates potential ambiguity.
Data Lineage Systems reduce that ambiguity by making data movement visible. They support end-to-end lineage from source origin to final output, enable pipeline impact analysis before changes are deployed, and preserve data flow traceability across technical and business systems.
For enterprises using external market signals in pricing, product strategy, competitive benchmarking, demand forecasting, compliance monitoring, or AI workflows, lineage is not optional documentation. It is an operational control. It helps teams understand what changed, where it came from, how it was processed, who depends on it, and whether the output can be trusted.
A structured review can help evaluate whether current market intelligence workflows have reliable lineage coverage, impact analysis, field-level traceability, and audit-ready metadata. You can run an external data infrastructure audit with our team to review your current setup and understand what is required to build a reliable, enterprise-scale external data infrastructure.


