Key Takeaways
- API Schema Management defines how request and response structures are designed, validated, changed, and governed across connected systems.
- API schema design should specify required fields, data types, allowed values, null behavior, timestamps, identifiers, and ownership expectations.
- A request response schema protects downstream consumers by making payload structure predictable before integrations reach production.
- A schema evolution strategy helps APIs change safely without breaking ERP, CRM, warehouse, BI, product, payment, marketplace, and operational systems.
- Strong API contract structure requires validation rules, ownership, review cycles, version awareness, audit trails, and consumer-impact analysis.
Enterprise API integrations often fail because the connection works, but the payload does not remain stable. An endpoint may respond successfully while returning a missing field, a changed data type, a new status value, or a nested object that downstream systems were not designed to process. The API is technically available, yet the integration becomes unreliable.
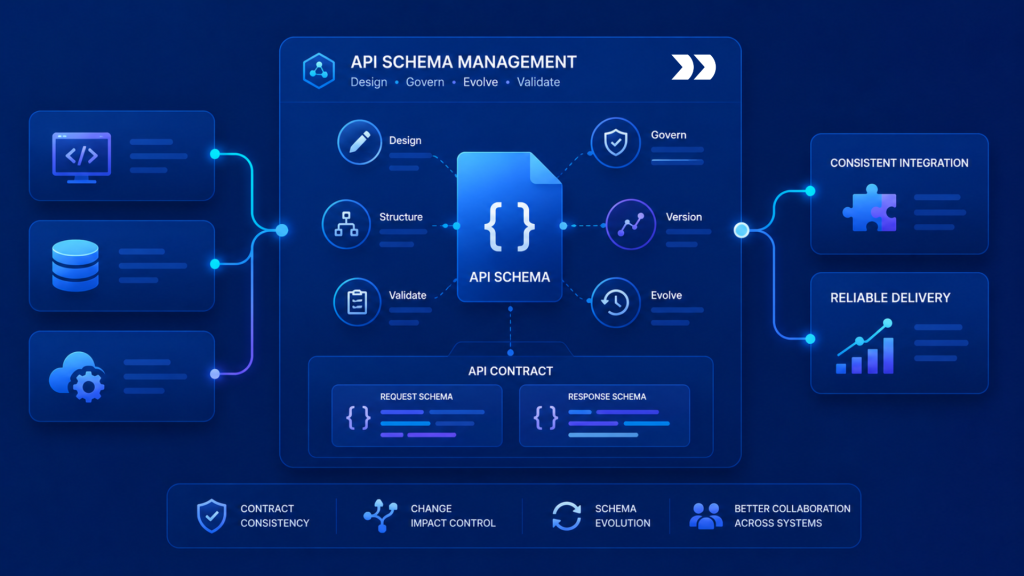
API Schema Management creates the control layer for request and response structures. It defines what an API expects, what it returns, which fields are required, how schemas evolve, and how consumers are protected from unexpected payload changes.
In cross-system integration programs, schema management is not API documentation alone. It is an operational reliability function. It determines whether ERP, CRM, warehouse, BI, AI, payment, marketplace, product, and supplier systems can exchange data without breaking downstream workflows.
Why API Schema Management Matters in Cross-System Integration
API Schema Management matters because enterprise APIs are reused across systems, teams, workflows, and business processes. A single customer endpoint may support CRM updates, billing synchronization, support workflows, analytics tables, and AI features. A product endpoint may support e-commerce, marketplaces, warehouse systems, and sales portals.
Deloitte’s current guidance on API governance for agentic AI argues that API strategy standardizes how APIs are designed, published, and reused so AI and enterprise integration can move from pilots to production. That standardization depends heavily on stable schema expectations, not only endpoint availability.
Why API Payload Structure Determines Integration Reliability
API reliability is not only measured by uptime or response time. It also depends on whether the payload structure remains valid for consuming systems. If a response field changes from string to object, a downstream parser may fail. If a required field becomes nullable, a warehouse load may accept incomplete records. Also, if a new status value appears without notice, BI logic may misclassify records.
A request-response schema defines the structure that producers and consumers rely on. It should clarify required fields, optional fields, data types, allowed values, nested objects, timestamp formats, identifiers, pagination rules, and error-response formats.
Without that structure, each consumer interprets the API independently. This creates inconsistent handling across systems and increases the chance that schema changes create production incidents.
How Weak Schema Control Creates Downstream Risk
Weak schema control creates risk because schema defects often move silently. A request may be accepted but processed incorrectly. A response may load into a warehouse but break downstream transformations. A product API may publish incomplete attributes to a marketplace. A customer API may sync records without required billing identifiers.
These problems become harder to resolve once multiple systems consume the same API. A schema change that seems minor to the producer may affect finance reporting, customer operations, product publishing, or AI feature generation.
Gartner’s 2025 Magic Quadrant for API Management notes that AI is transforming API management and creating new security and governance demands for resilient API ecosystems. In practice, schema governance is one of the controls needed to keep those ecosystems reliable as reuse expands.
API Schema Design for Enterprise Integrations
API schema design should begin with business meaning and operational use, not only field formatting. A schema describes the interface between systems. If the schema is unclear, every consumer must guess how to interpret the API.
A strong schema design defines structure, meaning, validation rules, ownership, and change expectations.
Defining Required Fields, Data Types, and Business Meaning
Required fields should reflect operational necessity. If a payment integration cannot process a transaction without a transaction ID, that field must be required. If a product catalog cannot be published without SKU, product name, category, and publication status, those fields must be enforced. Also, if a customer sync requires a canonical customer ID, the schema should make that expectation visible.
Data types must also be stable. A numeric field should not become text. A timestamp should follow a consistent format. A boolean should not quietly become a multi-state value. Nested objects should be defined clearly so consumers know what they can rely on.
Business meaning is equally important. A field called status is not enough. The schema should define what each status value means and when it applies. Otherwise, systems may comply technically while interpreting the payload differently.
Structuring API Requests Around Operational Controls
Request schemas should reflect the controls needed before data enters the target system. A product update request, for example, may need approval status, updated fields, target channel, timestamp, and source system. A customer update request may need the account ID, billing ID, updated fields, and validation policy.
A compact schema validation example can look like this:
PRODUCT_UPDATE_SCHEMA = {
"required_fields": ["event_type", "source_system", "sku", "updated_fields", "approval_status"],
"allowed_events": ["product.attribute_updated", "product.price_updated"],
"blocked_approval_statuses": ["pending", "rejected"],
}
def validate_product_update(payload):
missing = [field for field in PRODUCT_UPDATE_SCHEMA["required_fields"] if not payload.get(field)]
if missing:
return {"valid": False, "reason": "missing_required_fields", "fields": missing}
if payload.get("event_type") not in PRODUCT_UPDATE_SCHEMA["allowed_events"]:
return {"valid": False, "reason": "unsupported_event_type"}
if payload.get("approval_status") in PRODUCT_UPDATE_SCHEMA["blocked_approval_statuses"]:
return {"valid": False, "reason": "approval_not_ready"}
return {"valid": True}This kind of snippet should not be treated as a full implementation. It shows the operating principle: an API request should be validated against schema expectations before it is allowed to update downstream systems.
Designing Response Schemas for Consumer Stability
Response schemas should be designed for consumer stability. If multiple systems depend on an API response, the producer must avoid unnecessary structural changes. Consumers should know which fields are guaranteed, which fields are optional, and which fields may change.
Response schemas should include standard error structures. If every endpoint returns errors differently, consumers must build custom exception logic for each endpoint. A consistent error schema improves recovery, observability, and support workflows.
For enterprise APIs, response schemas should also include traceability fields where appropriate. Also, request ID, source system, schema version, timestamp, and processing status help consumers diagnose failures and reconcile records.
Request Response Schema Controls
Request response schema controls ensure that APIs behave predictably before and after production deployment. These controls should cover validation, compatibility, exception handling, and consumer notification.
The goal is not to make schemas rigid. The goal is to make the change controlled.
Validating Incoming Requests Before Processing
Incoming requests should be validated before business logic executes. This prevents malformed, incomplete, unauthorized, or unsupported payloads from entering operational systems.
Validation should check required fields, data types, allowed values, nested structures, timestamp formats, identifier formats, and business-rule conditions. If validation fails, the API should return a consistent error structure and route the payload for review when needed.
For example, a customer API may require crm_account_id, billing_customer_id, and updated_fields before publication:
CUSTOMER_REQUEST_RULES = {
"required_fields": ["event_type", "source_system", "crm_account_id", "billing_customer_id", "updated_fields"],
"publish_policies": ["publish_after_validation", "publish_immediately"],
}
def route_customer_request(payload):
missing = [field for field in CUSTOMER_REQUEST_RULES["required_fields"] if not payload.get(field)]
if missing:
return {"action": "quarantine", "reason": "missing_required_fields", "fields": missing}
if payload.get("sync_policy") == "publish_after_validation":
return {"action": "send_for_validation", "owner": "data_operations"}
if payload.get("sync_policy") not in CUSTOMER_REQUEST_RULES["publish_policies"]:
return {"action": "reject", "reason": "unsupported_sync_policy"}
return {"action": "publish"}This mirrors the earlier Cluster 5 code pattern: check the payload, route it to the correct path, and prevent unsafe publication.
Controlling Response Completeness and Field Guarantees
Response validation is as important as request validation. An API may accept a request and still return an incomplete or unexpected response. If a downstream system expects a canonical ID, status, timestamp, and processing result, those fields should be guaranteed.
A response schema should define which fields are always returned, which fields are conditional, and which fields are deprecated. It should also define how errors are returned so consumers do not need to infer failure from inconsistent messages.
In practice, response completeness protects consumers. BI systems, warehouses, operational workflows, and AI pipelines should not have to guess whether an API response is production-safe.
Schema Evolution Strategy for API Programs
The schema evolution strategy defines how API schemas change over time. Change is unavoidable. New fields are added. Business processes evolve. Systems migrate. Consumers need richer responses. Security requirements change. However, schema change must not break downstream operations unexpectedly.
NIST’s API protection guidance states that modern enterprise IT systems rely on APIs for integration that support organizational business processes, making secure and controlled API deployment important across the API lifecycle. Schema evolution should be managed as part of that lifecycle, not handled informally after changes ship.
Separating Breaking and Non-Breaking Schema Changes
Schema changes should be classified before release. Non-breaking changes may include adding optional fields, adding metadata, or expanding a response object without changing existing behavior. Breaking changes include removing fields, renaming fields, changing data types, changing required-field behavior, changing enum meaning, or altering nested structures used by consumers.
Some changes are technically non-breaking but operationally risky. Adding a new status value may not break parsing, but it can break business logic if consumers do not know how to classify the value. Changing the field meaning without changing the field name can be even more dangerous because systems may continue running while producing incorrect outputs.
A schema evolution strategy should define which changes require review, testing, consumer notification, and migration windows.
Managing Deprecation Without Breaking Consumers
Deprecation should be explicit. If a field, endpoint, or schema structure will be retired, consumers need notice, replacement guidance, migration timing, and visibility into the retirement schedule.
A deprecated field should not disappear suddenly. It should remain available during a defined transition period unless there is a security or compliance reason to remove it faster. Consumer usage should be tracked so teams know which applications still depend on the old schema.
This discipline is especially important in enterprise APIs because one endpoint may support many internal and external consumers. A schema retirement that looks simple to the producer may create large downstream remediation work.
Testing Schema Evolution Against Downstream Systems
Schema changes should be tested against downstream consumers before production release. This includes application clients, warehouse ingestion jobs, BI models, AI workflows, event consumers, and operational systems.
Testing should confirm that consumers can parse the new schema, required fields remain available, allowed values are understood, and response structures remain compatible. For critical integrations, schema changes should also be tested against realistic edge cases, not only ideal samples.
This turns schema evolution into controlled change management rather than reactive incident response.
API Contract Structure and Governance
API contract structure defines the agreement between API producers and consumers. It includes schema expectations, data meaning, change rules, ownership, service behavior, validation requirements, and operational guarantees.
A schema describes structure. A contract defines responsibility.
Defining Producer and Consumer Responsibilities
Producers are responsible for publishing stable schemas, documenting changes, validating payloads, and communicating breaking changes. Consumers are responsible for using supported versions, handling documented errors, validating responses, and migrating within agreed-upon windows.
This producer-consumer model reduces integration ambiguity. If an upstream system changes a payload, the contract should define how consumers are notified and how compatibility is tested. If a consumer sends invalid requests, the contract should define the error response and remediation path.
Without clear responsibilities, schema management becomes informal and incident-driven.
Connecting Schema Rules to API Governance
API schema rules should be part of governance. This includes review standards, naming conventions, field definitions, error structures, version rules, deprecation policies, and lifecycle controls.
Governance does not mean slowing every API change. It means applying the right review level based on risk. A low-impact optional field may need a lightweight review. A breaking change to customer, payment, product, or order APIs may require formal approval and consumer-impact analysis.
Deloitte’s API governance guidance emphasizes standardization, reuse, security, and reliability as API programs scale into AI and operational workflows. Schema governance is the practical mechanism that makes those priorities enforceable at the interface level.
Technology and Integration Considerations
API Schema Management should connect to development, integration, monitoring, and governance systems. Schema rules should not live only in documentation. They should be validated in pipelines, checked before deployment, and visible to downstream teams.
The technology layer should support schema documentation, automated validation, change review, consumer notification, and auditability.
Using API Gateways, CI/CD, Catalogs, and Validation Rules
API gateways can enforce request validation, authentication, routing, rate limits, and policy checks. CI/CD pipelines can test schemas before deployment. API catalogs can publish schema definitions, ownership, version status, and consumer guidance. Validation logic can check payloads before they update downstream systems.
The key is consistency. If every API team defines schemas differently, consumers face unpredictable integration behavior. Enterprise API programs should establish shared schema patterns, naming conventions, error formats, metadata fields, and change rules.
This makes cross-system integration more repeatable and reduces the operational burden on downstream teams.
Connecting API Schemas to Warehouses, BI, AI, and Lineage Systems
API schemas should remain visible after data enters downstream environments. Warehouses should preserve source API metadata, request IDs, schema versions, and load status where relevant. BI systems should understand which schema version supports a metric or dimension. AI workflows should know which API structure produced a feature or training input.
Lineage systems should connect API payloads to downstream tables, reports, models, and operational workflows. If a schema changes, teams should be able to identify affected consumers before production issues appear.
This visibility turns API schema management into enterprise integration infrastructure, not just API documentation.
Governance and Auditability in API Schema Management
Governance defines who owns schemas, who approves changes, how consumers are notified, and how violations are handled. Auditability preserves the evidence behind schema decisions.
The OECD’s work on data governance frames governance as the technical, policy, and regulatory structures required to manage data across its value cycle. API Schema Management fits this model because schema decisions affect how data moves, transforms, gets consumed, and remains accountable across systems.
Creating Ownership, Review Cycles, and Approval Paths
Each API schema should have an owner. Ownership should include the producing system, technical maintainer, business domain owner, and governance contact where relevant. Critical schemas should have stronger review cycles than low-risk internal APIs.
Review should occur when new fields are added, required fields change, response structures change, schema versions are retired, or new consumers are added. Approval paths should reflect operational impact. A change to a product description API may require product governance review. A change to payment or customer APIs may require security, finance, or compliance input.
Clear ownership prevents schema issues from becoming cross-team confusion.
Maintaining Audit Trails for Schema Changes and Consumer Impact
Audit trails should capture schema versions, field changes, approval records, breaking-change classification, deprecation notices, consumer notifications, validation failures, and production release dates.
Auditability matters when downstream results are challenged. Teams should be able to show which schema version was active, what changed, who approved it, and which consumers were affected.
For enterprise integration programs, this is procurement and governance reassurance. It shows that API schemas are not changed informally when downstream operations depend on them.
Conclusion: Turning API Schemas into Controlled Integration Infrastructure
API Schema Management helps enterprises control the structure and meaning of data exchanged through APIs. It defines request-response schema expectations, API schema design standards, schema evolution strategy, and API contract structure before downstream systems depend on the interface.
Strong schema management prevents missing fields, unexpected values, type changes, unstable responses, and breaking changes from propagating into ERP, CRM, warehouse, BI, AI, product, payment, marketplace, and operational systems. It gives producers and consumers a shared operating model for reliable integration.
The capability matters because APIs are not just technical endpoints. They are contracts between systems. When those contracts are governed, validated, version-aware, and auditable, API integration becomes a scalable enterprise infrastructure layer.
A structured review can help evaluate whether current API workflows have reliable API Schema Management, api schema design controls, schema evolution strategy, request response schema validation, and audit-ready api contract structure. You can run an external data infrastructure audit with our team to review your current setup and understand what is required to build a reliable, enterprise-scale API integration infrastructure.


