
Key Takeaways
- Why multi-source web data extraction introduces architectural complexity
- How web scraping architecture supports scalable data acquisition
- How web scraping infrastructure enables reliable large-scale data extraction
- How normalization and entity resolution ensure cross-source consistency
- How monitoring and governance maintain pipeline reliability
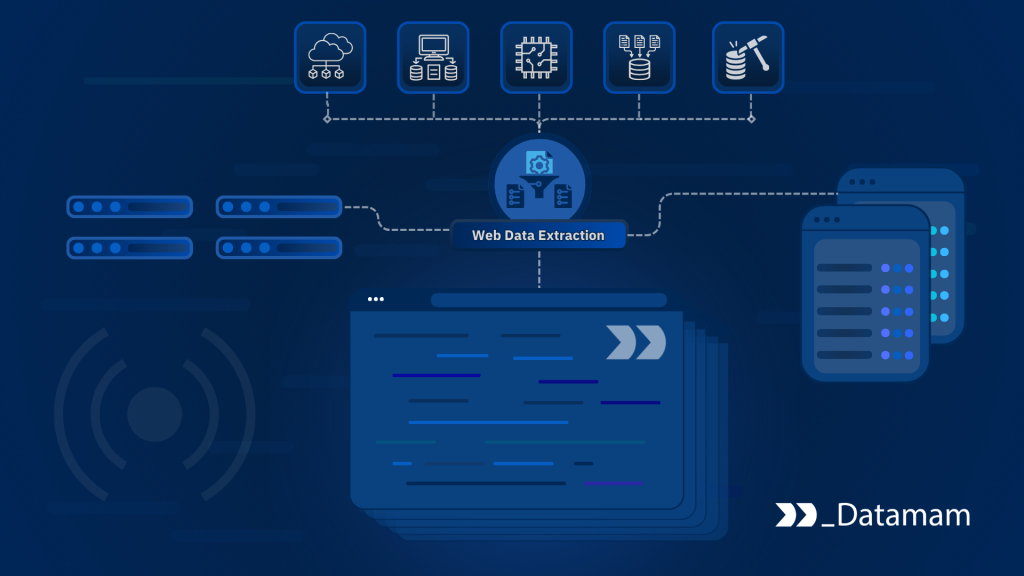
Modern enterprises depend on web data extraction to capture signals from marketplaces, competitor platforms, public datasets, and digital ecosystems that operate outside internal systems. However, extracting data from a single source is fundamentally different from designing infrastructure capable of ingesting and maintaining data across hundreds or thousands of sources simultaneously.
As organizations scale external data operations, they encounter structural fragmentation, access limitations, and operational instability. Designing multi-source extraction systems, therefore, becomes an infrastructure challenge rather than a collection task. Reliable systems must integrate distributed crawling, normalization, monitoring, and governance into a unified architecture capable of sustaining enterprise-scale data flows.
Why Multi-Source Web Data Extraction Is Architecturally Complex
Multi-source environments introduce variability that does not exist in single-source pipelines. Each platform differs in structure, update frequency, and access constraints. As the number of sources increases, complexity grows nonlinearly, requiring systems that can adapt dynamically.
According to Gartner’s data and analytics trends, organizations increasingly require scalable and governed data architectures to support continuous data ingestion and AI-driven decision environments.
Diversity of External Data Environments
Enterprise web data extraction systems must operate across a wide range of digital environments. These include online marketplaces, competitor platforms, structured APIs, and public datasets, each with distinct access methods and update patterns.
Unlike internal systems, external environments are not standardized. Data structures vary, access rules differ, and content may be dynamically generated. As a result, extraction systems must support flexible ingestion mechanisms capable of handling diverse data formats and delivery models.
Structural Fragmentation Across Sources
Even when data is successfully extracted, structural inconsistencies create additional challenges. Fields may be named differently across platforms, taxonomies may not align, and formats such as currency, units, and timestamps may vary significantly.
This fragmentation prevents direct comparison across sources. Without structured alignment mechanisms, datasets remain isolated and cannot support cross-market analysis or unified analytics models.
Core Architecture of Multi-Source Web Scraping Systems
To operate reliably at scale, web scraping architecture must support distributed processing, adaptive access strategies, and parallel extraction across multiple environments. Systems must be designed for resilience, ensuring that failures in individual sources do not disrupt overall data flows.
Distributed Crawling and Parallel Extraction
Large-scale distributed web scraping systems rely on parallel extraction processes to collect data from multiple sources simultaneously. Distributed crawlers operate across multiple nodes, enabling systems to scale horizontally as the number of monitored sources increases.
This approach reduces latency and ensures that high-frequency updates can be captured without overloading individual components. Parallelization also improves fault tolerance, allowing systems to continue operating even when specific extraction jobs fail.
Access Management and Network Distribution
Accessing external platforms at scale requires robust web scraping infrastructure that can manage network distribution and avoid access restrictions.
This includes:
- IP rotation strategies that distribute requests across multiple addresses
- Geographic routing to simulate region-specific access patterns
- Session and authentication handling for protected environments
Without structured access management, extraction systems risk being blocked or throttled, disrupting pipeline continuity and reducing data reliability.
As multi-source extraction systems scale, it becomes increasingly difficult to identify where reliability, access stability, or data consistency issues are introduced.
You can run an external data infrastructure audit with our team to review your current setup and understand what is required to build a reliable, enterprise-scale external data infrastructure.
Normalization and Entity Resolution Across Data Sources
Once data is extracted, the challenge shifts from acquisition to consistency. Multi-source datasets must be standardized and aligned before they can support enterprise analytics.
According to the OECD, consistent data standards are essential for enabling reliable cross-platform analysis and data-driven decision-making across digital ecosystems.
Schema Alignment and Structured Data Mapping
Different sources often represent the same information using different structures. Schema alignment ensures that fields from multiple sources map into a unified data model.
This process includes:
- Aligning attribute names across datasets
- Standardizing formats for numerical and temporal data
- Mapping source-specific taxonomies into consistent categories
Without schema alignment, datasets cannot be integrated effectively, limiting their usefulness in analytics systems.
Entity Matching and Deduplication Logic
A critical challenge in multi-source data extraction is identifying when different records refer to the same entity.
Entity matching systems resolve this by linking records across sources based on shared attributes. This process may involve comparing product identifiers, names, or other distinguishing features to establish relationships between datasets.
Deduplication ensures that identical records are not counted multiple times, preserving data accuracy and preventing distortions in analytical outputs.
For a broader architectural explanation of how normalization, validation, and monitoring integrate across enterprise systems, see our Enterprise Data Collection Services infrastructure analysis.
Operational Monitoring and System Resilience
Multi-source systems require continuous monitoring to maintain reliability. External environments change frequently, and extraction systems must detect and adapt to these changes in real time.
According to NIST, continuous monitoring and validation are essential for maintaining trustworthy data systems, particularly in environments that support automated decision-making. Implementing continuous monitoring in data analysis enables organizations to respond swiftly to discrepancies and anomalies. By leveraging advanced analytics and machine learning algorithms, businesses can enhance their ability to identify trends and make informed decisions based on real-time insights. This proactive approach not only improves data quality but also supports strategic initiatives across various sectors.
Detecting Source Structure Changes
External platforms regularly modify layouts, APIs, and data structures. These changes can break extraction logic, leading to incomplete or incorrect datasets.
Monitoring systems must therefore detect structural changes as they occur and trigger adjustments to extraction workflows. This ensures that pipelines remain functional even as external environments evolve.
Maintaining Pipeline Continuity at Scale
Reliability in large scale web data extraction depends on continuous oversight. Monitoring systems track pipeline performance, identify failures, and ensure that data flows remain uninterrupted.
This includes tracking:
- Extraction success rates
- Data completeness
- Latency across ingestion processes
These controls allow organizations to maintain consistent data availability, even as system complexity increases.
Technology Stack and Infrastructure Behind Web Data Extraction Systems
Enterprise-grade web data extraction systems rely on coordinated technologies that operate across ingestion, processing, validation, and governance layers. At scale, infrastructure must support continuous data flows while maintaining observability and control.
Orchestration and Distributed Processing
Extraction workflows are typically coordinated using Apache Airflow, which manages dependencies across data pipelines. Distributed processing frameworks such as Apache Spark enable large-scale transformation and enrichment, while Apache Kafka supports real-time data ingestion.
Data Collection and Automation Layers
Automation frameworks such as Playwright enable interaction with dynamic web environments, allowing systems to extract data from complex interfaces and authenticated platforms.
Validation, Monitoring, and Observability
Validation frameworks like Great Expectations enforce data quality rules, while observability systems such as Prometheus monitor pipeline health and detect failures.
These systems prevent silent degradation and ensure that extracted data remains consistent and reliable.
Storage, Modeling, and Governance
Structured data is stored in platforms such as Snowflake, BigQuery, or Databricks, where it supports analytics and AI workflows. Transformation tools like dbt ensure consistent modeling, while governance systems track lineage, access, and compliance.
In this context, web scraping infrastructure operates as a governed and observable system rather than a collection of extraction scripts.
Designing Scalable Continuous Data Monitoring Infrastructure
As extraction systems expand, scalability becomes a defining factor. Infrastructure must support increasing volumes of data, additional sources, and higher update frequencies without compromising reliability.
Scalable systems rely on distributed architectures, automated validation layers, and integration with enterprise analytics platforms. These capabilities ensure that extracted data remains accessible and actionable across the organization.
Multi-Source Web Data Extraction as Enterprise Infrastructure
The transition from isolated extraction to multi-source systems reflects a broader shift in enterprise data strategy. Organizations increasingly depend on external signals that evolve continuously, requiring infrastructure capable of capturing and integrating data at scale.
For a broader architectural perspective on how multi-source extraction integrates with validation and monitoring systems, see our Enterprise Data Collection Services infrastructure analysis.
Ultimately, web data extraction becomes a foundational capability that supports analytics, AI systems, and strategic decision-making. Organizations that invest in structured architecture, normalization, and monitoring systems build resilient data ecosystems capable of adapting to rapidly evolving digital environments.
Evaluate Your Data Acquisition Architecture
As external data becomes critical to analytics, pricing, and AI systems, infrastructure decisions around web data extraction require structured evaluation.
You can run an external data infrastructure audit with our team to review your current setup and understand what is required to build a reliable, enterprise-scale external data infrastructure.


